In the realm of cybersecurity, automation is not just a convenience but a necessity. Having a tool that can effortlessly construct endpoints and interconnect various security tools can revolutionize your workflow. Today, I’m excited to introduce you to Node-RED, a powerhouse for such tasks.
This is part of a series of hacking tools automated with Node-RED.
Setup
While diving into the intricacies of setting up a Kali VM with Node-RED is beyond the scope of this blog post, I’ll offer some guidance to get you started.
Base OS
To begin, you’ll need a solid foundation, which is where Kali Linux comes into play. Whether you opt for a virtual machine setup or use it as the primary operating system for your Raspberry Pi, the choice is yours.
Once you’ve got Kali Linux up and running, the next step is to install Node-RED directly onto your machine, NOT in a Docker container since you will ned root access to the host system. Follow the installation guide provided by the Node-RED team.
To ensure seamless operation, I highly recommend configuring Node-RED to start automatically at boot. One effective method to achieve this is by utilizing PM2.
By following these steps, you’ll have Node-RED set up and ready to streamline your cybersecurity automation tasks.
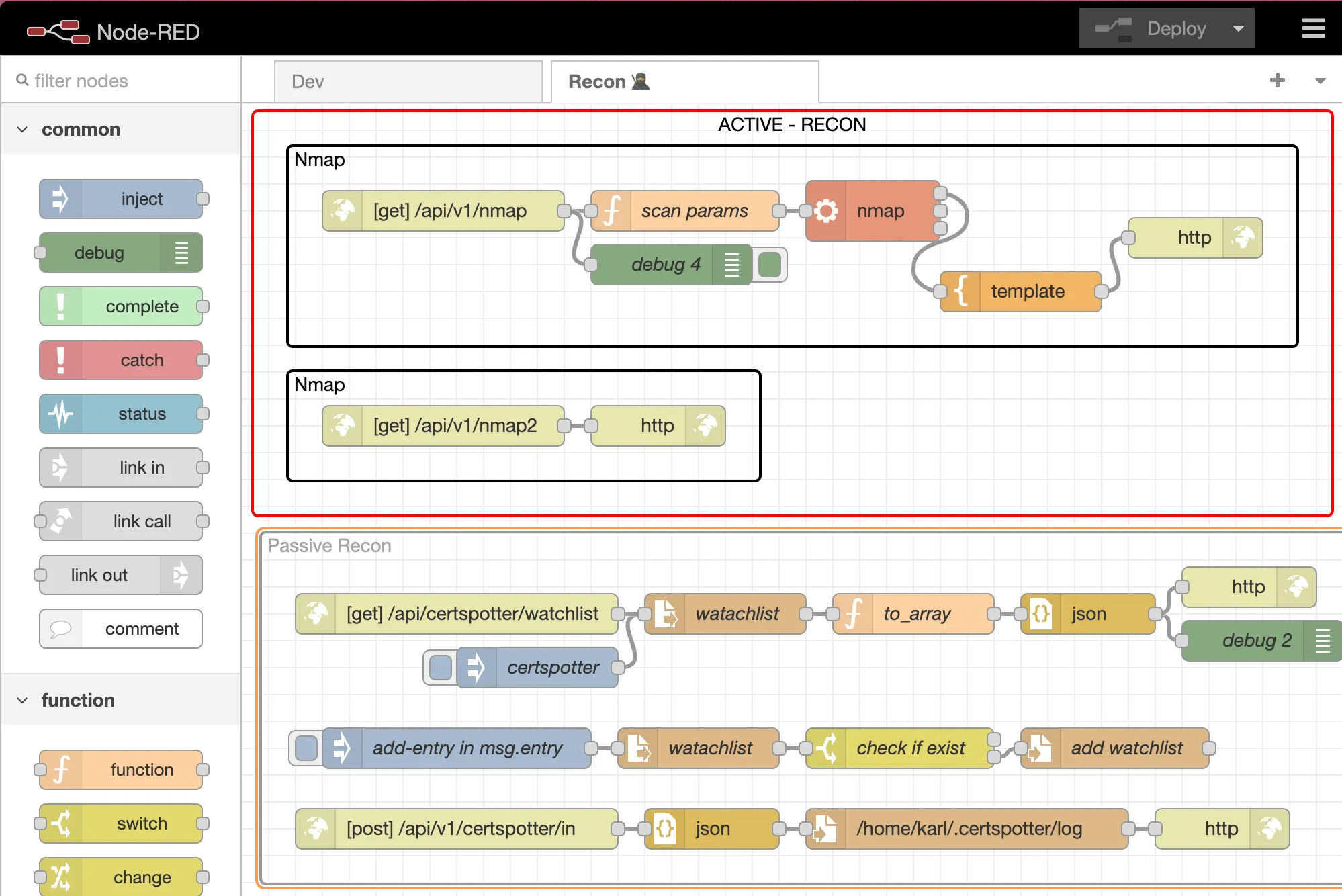
Nmap as a Service
In this section, we’ll create a web service that executes Nmap scans, accessible via a URL like so: http://10.10.0.11:8080/api/v1/nmap?target=exploit.to (Note: Your IP, port, and target will differ).
Building the Flow
To construct this service, we’ll need to assemble the following nodes:
HTTP In
Function
Exec
Template
HTTP Response
That’s all it takes.
You can define any path you prefer for the HTTP In node. In my setup, it’s /api/v1/nmap.
The function node contains the following JavaScript code:
It’s worth noting that this scan needs to be run as a root user due to the -sS flag (learn more here). The msg.payload.target parameter holds the ?target= value. While in production, it’s crucial to filter and validate input (e.g., domain or IP), for local testing, it suffices.
The Exec node is straightforward:
It simply executes Nmap and appends the msg.payload from the previous function node. So, in this example, it results in:
Bash
nmap-sS-Pn-T3exploit.to
The Template node formats the result for web display using Mustache syntax:
<pre>{{payload}}</pre>
Finally, the HTTP Response node sends the raw Nmap output back to the browser. It’s important to note that this setup isn’t suitable for extensive Nmap scans that take a while, as the browser may timeout while waiting for the response to load.
You now have a basic Nmap as a Service.
TODO
You can go anywhere from here, but I would suggest:
add validation to the endpoint
add features to supply custom nmap flags
stream result to browser via websocket
save output to database or file and poll another endpoint to check if done
format output for web (either greppable nmap or xml)
ChatOps (Discord, Telegram bot)
Edit 1:
I ended up adding validation for domain and IPv4. I also modified the target variable. It is now msg.target vs. msg.payload.target.
In today’s digital age, the internet is saturated with advertisements and trackers, leading to slower browsing speeds and potential security threats. To combat these issues, leveraging AdGuard Home as a central ad blocker provides several key benefits, such as improved security and faster internet speeds. While browser plugins like “uBlock Origin” offer protection for individual devices within specific browsers, they fall short in safeguarding all devices, particularly those without browser support, such as IoT devices.
Enhanced Security
AdGuard Home blocks intrusive ads and potentially harmful websites before they even reach your devices. By filtering out malicious content, AdGuard Home significantly reduces the risk of malware infections and phishing attacks, safeguarding your personal information and sensitive data.
Protecting Privacy
Ads often come bundled with tracking scripts that monitor your online behavior, compromising your privacy. With AdGuard Home, you can prevent these trackers from collecting your data, preserving your anonymity and preventing targeted advertising based on your browsing habits.
Faster Internet Speeds
Advertisements consume valuable bandwidth and resources, leading to slower loading times and sluggish internet performance. By eliminating ads and unnecessary tracking requests, AdGuard Home helps optimize your network’s efficiency, resulting in faster page loading speeds and smoother browsing experiences.
Open-Source and Transparent
AdGuard Home is open-source software, meaning its source code is freely available for scrutiny and verification by the community. This transparency fosters trust and ensures that the software operates with integrity, free from hidden agendas or backdoors.
Hosting AdGuard Home
Now that you understand why you would want a central adblocker in your home network let’s get started in setting it up.
First you need to decide if you want to host locally or in the cloud.
Hosting locally:
Benefits:
easier setup
more secure
private
Drawbacks:
need a server
Cloud hosting:
Benefits:
no local server
better uptime
Drawbacks:
more setup for same privacy and security
Since DNS is not encrypted, like HTTPS for example, the cloud provider will most likely be able to see you DNS queries. You will need to use DNS-over-TLS or DNS-over-HTTPS. In a home network it is usually okay to use regular DNS, because AdGuard Home itself uses DNS-over-*S resolvers to get the final address. An example of Cloudflare’s resolvers
Depending on your setup, you might already have a server, Home Assistant, pfSesne firewall or nothing at all. I am going to assume you do not have any of the above. So first of all you will need to repuporse an old PC or somethign like a Raspberry Pi (which i highly recommend, i own 7).
I have personally run AdGuard Home in a reasoably sized home network on a Raspberry Pi Zero W. I recommend a bigger one, but if you’re on a really tight budget, that is probably your best bet.
Once you have a machine and it is running a Linux distribution of your choice, you now can install AdGuard Home either in a Container or directly.
That is it. You might have to copy the start command which will be shown in your terminal before you can set up your AdGuard in the browser.
Web UI
The steps for AdGuard in the Web UI are self explanatory so I did not go into detail here. You are basically good to go. I recommend 2 things:
Go to Filters > DNS blocklists, then click on “Add blocklist” and select every Security list. I have also enabled all the “General” blocklists and not trouble.
Go to Settings > DNS settings, I have the following upstream DNS server:
I think most of the readers will have a Fritz!Box so this is what I will show here. The setup is probably very similar on your router. You basically just have to edit the DNS server settings in your router.
Fritz!Box
I did not show you my DNS Server IP by mistake. Scroll to the end to find out why. 9.9.9.9 is the Quad9 DNS Server, I use this in case my AdGuard goes down, otherwise I would not be able to browse the web.
Bonus
You are welcome to use my public AdGuard Home instance at 130.61.74.147, just enter it into your router. Please be advised that i will be able to see you DNS logs, which means I would know what you do on the internet… I do not care to be honest so you are free to make your own choice here.
Welcome to the world of cybersecurity, where adversaries are always one step ahead, cooking up new ways to slip past our defenses. One technique that’s been causing quite a stir among hackers is HTML and SVG smuggling. It’s like hiding a wolf in sheep’s clothing—using innocent-looking files to sneak in malicious payloads without raising any alarms.
Understanding the Technique
HTML and SVG smuggling is all about exploiting the blind trust we place in web content. We see HTML and SVG files as harmless buddies, used for building web pages and creating graphics. But little do we know, cybercriminals are using them as Trojan horses, hiding their nasty surprises inside these seemingly friendly files.
How It Works
So, how does this digital sleight of hand work? Well, it’s all about embedding malicious scripts or payloads into HTML or SVG files. Once these files are dressed up and ready to go, they’re hosted on legitimate websites or sent through seemingly harmless channels like email attachments. And just like that, attackers slip past our defenses, like ninjas in the night.
Evading Perimeter Protections
Forget about traditional attack methods that rely on obvious malware signatures or executable files. HTML and SVG smuggling flies under the radar of many perimeter defenses. By camouflaging their malicious payloads within innocent-looking web content, attackers can stroll right past firewalls, intrusion detection systems (IDS), and other security guards without breaking a sweat.
Implications for Security
The implications of HTML and SVG smuggling are serious business. It’s a wake-up call for organizations to beef up their security game with a multi-layered approach. But it’s not just about installing fancy software—it’s also about educating users and keeping them on their toes. With hackers getting sneakier by the day, we need to stay one step ahead to keep our digital fortresses secure.
The Battle Continues
In the ever-evolving world of cybersecurity, HTML and SVG smuggling are the new kids on the block, posing a serious challenge for defenders. But fear not, fellow warriors! By staying informed, adapting our defenses, and collaborating with our peers, we can turn the tide against these digital infiltrators. So let’s roll up our sleeves and get ready to face whatever challenges come our way.
Enough theory and talk, let us get dirty ! 🏴☠️
Being malicious
At this point I would like to remind you of my Disclaimer, again 😁.
I prepared a demo using a simple Cloudflare Pages website, the payload being downlaoded is an EICAR test file.
Here is the Page: HTML Smuggling Demo <- Clicking this will download an EICAR test file onto your computer, if you read the Wikipedia article above you understand that this could trigger your Anti-Virus (it should).
Here is the code (i cut part of the payload out or it would get too big):
This HTML smuggling at its most basic. Just take any file, encode it in base64, and insert the result into var file = "BASE64_ENCODED_PAYLOAD";. Easy peasy, right? But beware, savvy sandbox-based systems can sniff out these tricks. To outsmart them, try a little sleight of hand. Instead of attaching the encoded HTML directly to an email, start with a harmless-looking link. Then, after a delay, slip in the “payloaded” HTML. It’s like sneaking past security with a disguise. This delay buys you time for a thorough scan, presenting a clean, innocent page to initial scanners.
By playing it smart, you up your chances of slipping past detection and hitting your target undetected. But hey, keep in mind, not every tactic works every time. Staying sharp and keeping up with security measures is key to staying one step ahead of potential threats.
Advanced Smuggling
If you’re an analyst reading this, you’re probably yawning at the simplicity of my example. I mean, come on, spotting that massive base64 string in the HTML is child’s play for you, right? But fear not, there are some nifty tweaks to spice up this technique. For instance, ever thought of injecting your code into an SVG?
You can stash the SVG in a CDN and have it loaded at the beginning of your page. It’s a tad more sophisticated, right? Just a tad.
Now, I can’t take credit for this genius idea. Nope, the props go to Surajpkhetani, his tool also gave me the idea for this post. I decided to put my own spin on it and rewrote his AutoSmuggle Tool in JavaScript. Why? Well, just because I can. I mean, I could have gone with Python or Go… and who knows, maybe I will someday. But for now, here’s the JavaScript code:
Essentially it generates you HTML pages or SVG “images” simply by going:
nodeautosmuggler.cjs-ivirus.exe-ohtml
I’ve dubbed it HTMLSmuggler. Swing by my GitHub to grab the code and take a peek. But hold onto your hats, because I’ve got big plans for this little tool.
In the pipeline, I’m thinking of ramping up the stealth factor. Picture this: slicing and dicing large files into bite-sized chunks like JSON, then sneakily loading them in once the page is up and running. Oh, and let’s not forget about auto-deleting payloads and throwing in some IndexedDB wizardry to really throw off those nosy analysts.
I’ve got this wild notion of scattering the payload far and wide—some bits in HTML, others in JS, a few stashed away in local storage, maybe even tossing a few crumbs into a remote CDN or even the URL itself.
The goal? To make this baby as slippery as an eel and as light as a feather. Because let’s face it, if you’re deploying a dropper, you want it to fly under the radar—not lumber around like a clumsy elephant.
The End
Whether you’re a newbie to HTML smuggling or a seasoned pro, I hope this journey has shed some light on this sneaky technique and sparked a few ideas along the way.
Thanks for tagging along on this adventure through my musings and creations. Until next time, keep those creative juices flowing and stay curious! 🫡
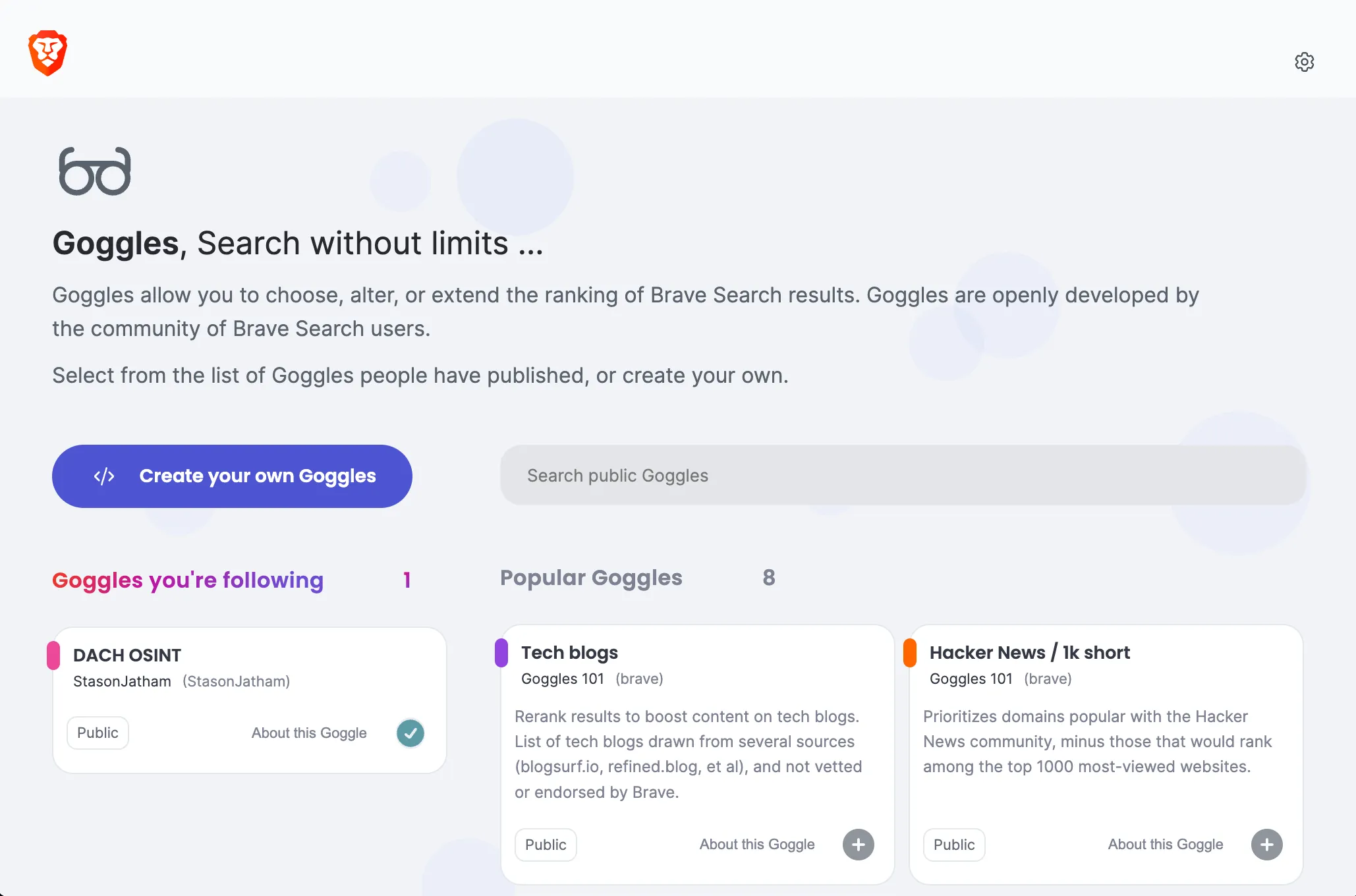
The world’s most potent OSINT (Open Source Intelligence) tools are search engines. They collect, index, and aggregate all the freely available information on the internet, essentially encapsulating the world’s knowledge. Nowadays, the ability to enter a topic in a search bar and receive results within milliseconds is often taken for granted. Personally, I’ve developed a profound appreciation for this technology by constructing my own search engines from scratch using Golang. But let’s dive into our topic – have you ever tried Googling your own name?
Brave Search
Today, I want to shine a light on Brave Search (Brave Search docs). In 2022, Brave introduced a remarkable yet underappreciated feature known as Goggles. Described on the Brave Goggles website as follows:
Goggles allow you to choose, alter, or extend the ranking of Brave Search results. Goggles are openly developed by the community of Brave Search users.
Here’s a straightforward example:
$boost=1,site=facebook.com
This essentially boosts search results found on the facebook.com domain, elevating them higher in the results. The syntax is straightforward and limited; you can find an overview here.
Pattern Matching:
Plain-text pattern matching in URLs: /this/is/a/pattern
Globbing capabilities using ’*’ to match zero, one, or more characters: /this/is/*/pattern
Use of ’^’ to match URL delimiters or end-of-URL: /this/is/a/pattern^
Anchoring:
Use of ’|’ character for prefix or suffix matches in URLs.
Prefix: |https://en.
Suffix: /some/path.html|
Options:
‘site=’ option to limit instructions to specific websites based on their domain: $site=brave.com
Actions:
‘boost’: Boost the ranking of matched results: /r/brave_browser/$boost or $boost=4,site=test.de
‘downrank’: Downrank the ranking of matched results: /r/google/$downrank
Adjust the strength of boosting or downranking actions (limited to a maximum value of 10): /r/brave_browser/$boost=3
Combining Instructions:
Combine multiple instructions to express complex reranking functions with a comma ”,”: /hacking/$boost=3,site=github.com
Finding Goggles
Now that you have a basic idea of how to construct Goggles, you can find prebuilt ones here.
A search for “osint” reveals my very own creation, the world’s first public 🎉 OSINT Goggle.
When building your own Goggle, it needs to be hosted on GitHub or Gitlab. I host mine here on GitHub.
DACH OSINT Goggle
Here’s my code:
!name:DACHOSINT!description:OSINTGogglefortheDACH (Germany, Austria,andSwitzerland) Region. Find out more on my blog [exploit.to](https://exploit.to/)!public:true!author:StasonJatham!avatar:#ec4899!GermanPlatforms$boost=4,site=telefonbuch.de$boost=4,site=dastelefonbuch.de$boost=4,site=northdata.de$boost=4,site=unternehmensregister.de$boost=4,site=firmen.wko.at!Smallboostforsocialmedia$boost=1,site=facebook.com$boost=1,site=twitter.com$boost=1,site=linkedin.com$boost=1,site=xing.com!Onlinereviews$boost=2,site=tripadvisor.de$boost=2,site=tripadvisor.at$boost=2,site=tripadvisor.ch!Personal/Businesscontactinformation,pathboost/kontakt*$boost=3/datenschutz*$boost=3/impressum*$boost=3!Generalboost,wordsincludedinpages*mail*$boost=1,site=de*mail*$boost=1,site=at*mail*$boost=1,site=ch*adresse*$boost=1,site=de*adresse*$boost=1,site=at*adresse*$boost=1,site=ch*verein*$boost=1!Personalemail*gmx*$boost=1*web*$boost=1*t-online*$boost=1*gmail*$boost=1*yahoo*$boost=1*Postadresse*$boost=1
I believe it’s self-explanatory; the aim is to prioritize results that commonly contain personal information. However, it’s still a work in progress, and I plan to add more filters to these rules.
Rule Development
Rant Alert: Developing these rules can be quite frustrating. You have to push your rule to GitHub, then enter the URL in the Goggle upload and hope that you don’t encounter any cached results. The error messages received are often useless; most of the time, you just get something like “cannot compile.” In the future, I earnestly hope for an online editor or VSCode support. If the frustration persists, I might consider building it myself. Despite these challenges, writing these rules is generally straightforward.
Future
I hope the Brave team prioritizes this feature, and more people embrace it. They’ve hinted at more advanced filter rules akin to those found on Google, such as “intitle,” which, in my opinion, would make this the most powerful search engine on the planet.
I also intend to focus on malware research, aiming to refine searches to uncover information about whether a particular file, domain, or email is known to be malicious.
Please take a look at my Goggle and try it out for yourself. Provide feedback, spread the word, and create your own Goggles to give this feature the love it deserves.
An alternative server implementation of the Bitwarden Client API, written in Rust and compatible with official Bitwarden clients [disclaimer], perfect for self-hosted deployment where running the official resource-heavy service might not be ideal.
If you’re unfamiliar with Vaultwarden or Bitwarden, here’s a quick primer: Vaultwarden is a self-hosted password manager that allows you to securely access your credentials via web browsers, mobile apps, or desktop clients. Unlike traditional cloud-based solutions, Vaultwarden is designed for those of us who value control over our data and want a “syncable” password manager without the resource-heavy overhead.
Since anything that isn’t self-hosted or self-administered is out of the question for me, Vaultwarden naturally caught my attention. Its lightweight design is perfect for a minimal resource setup. Here’s what I allocated to my Vaultwarden instance:
• Alpine LXC
• 1 CPU Core
• 1 GB RAM
• 5 GB SSD Storage
And let me tell you, this thing is bored. The occasional uptick in memory usage you might notice is mostly me testing backups or opening 20 simultaneous sessions across devices—so not even Vaultwarden’s fault. To put it simply: you could probably run this on a smart toaster, and it would still perform flawlessly.
Why I Tried Vaultwarden
Initially, I came across Vaultwarden while exploring the Proxmox VE Helper Scripts website and thought, “Why not give it a shot?” The setup was quick, and I was immediately impressed by its sleek, modern UI. Since Vaultwarden is compatible with Bitwarden clients, you get the added bonus of using the polished Bitwarden desktop app and its functional, albeit less visually appealing, browser extension.
My main motivation for trying Vaultwarden was to move away from syncing my KeePass database across Nextcloud and iCloud. This process had become tedious, especially when setting up new development environments or trying out new Linux distributions—something I do frequently.
Each time, I had to manually copy over my KeePass database, which meant logging into Nextcloud to retrieve it—a task that was ironically dependent on a password stored inside KeePass, which I didn’t have access to yet. With Vaultwarden, I can simply open a browser, enter my master password, and access everything instantly.
Yes, it’s only one or two steps less than my KeePassXC workflow, but sometimes those minor annoyances add up more than they should. Vaultwarden’s seamless syncing across devices has been a breath of fresh air.
Is KeePassXC Bad? Not at All! Here’s Why I Still Love It
Over the years, KeePassXC has been an indispensable tool for managing my passwords and SSH keys. Even as new solutions like Vaultwarden (a self-hosted version of Bitwarden) gain popularity, KeePassXC continues to hold its ground, excelling in several areas where others fall short. Here’s a detailed breakdown of why I still rely on KeePassXC and how it outshines alternatives like Vaultwarden and Bitwarden.
Why KeePassXC Stands Out (in my opinion)
1. Superior Password Generator
KeePassXC’s default password generator is leaps and bounds ahead of the competition. Its design is both powerful and intuitive, offering extensive customization without overwhelming the user. You can effortlessly fine-tune the length, complexity, and character set of generated passwords, making it ideal for advanced use cases.
2. SSH Agent Integration
If you work with multiple SSH keys (I manage over 100), KeePassXC’s built-in SSH agent is a game-changer. It allows seamless integration and management of SSH keys alongside your passwords, streamlining workflows for developers and sysadmins alike. This feature alone makes KeePassXC a must-have for me.
3. File and Hidden Text Storage
Unlike Bitwarden, which doesn’t currently support file storage, KeePassXC offers advanced options for securely storing files and hidden text.
Why I’m Running KeePassXC and Vaultwarden in Parallel
While I’ve started using Vaultwarden for some tasks, there are still key features in KeePassXC that I simply can’t live without:
Local-Only Security:
KeePassXC keeps everything offline by default, which eliminates the risks of exposing passwords to the internet. Even though I host Vaultwarden behind a VPN for added peace of mind, there’s something inherently reassuring about KeePassXC’s local-first approach.
Privacy vs. Accessibility:
Vaultwarden offers enough security features like MFA, WebAuthn or hardwaretoken to safely expose it online, but the idea of having my passwords accessible over the internet still feels unsettling. For that reason, KeePassXC remains my go-to for my most sensitive credentials. I am probably just paranoid, hosting it behind Cloudflare and a firewall with a Client certificate would add sufficient security (on top) where you would not have to worry.
Unique Features:
There are small yet critical features in KeePassXC, like its file storage capabilities and SSH agent integration, that Vaultwarden simply lacks at the moment.
What Vaultwarden Does Well
To give credit where it’s due, Vaultwarden brings some compelling features to the table. One standout is the reporting feature, which alerts you to compromised passwords. It’s a fantastic tool for staying on top of security best practices, I am also a huge fan of web based tools and I like the UI and UX in general.
Conclusion
Both KeePassXC and Vaultwarden have their strengths, and which one you choose ultimately depends on your priorities. For me, KeePassXC remains the gold standard for password management, offering unparalleled functionality for advanced users. Vaultwarden complements it well for “cloud”-based access and reporting, but it still has a long way to go before it can replace KeePassXC in my workflow.
For now, running both in parallel strikes the perfect balance between security, usability, and convenience. Since I am running Vaultwarden on my Proxmox, which is already handling all my backup tasks, I also do not have to worry about data loss or doing extra work.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.



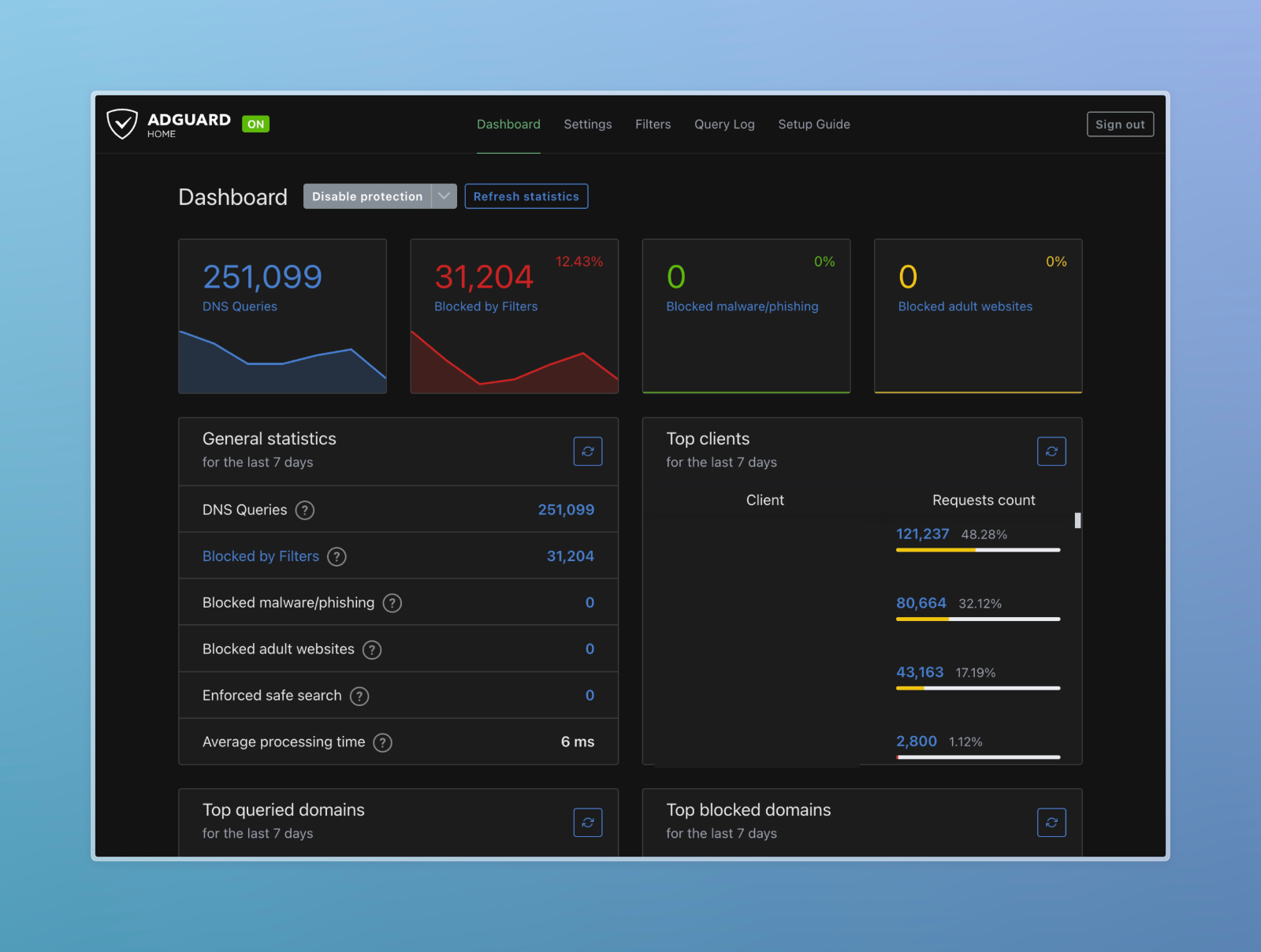
 I did not show you my DNS Server IP by mistake. Scroll to the end to find out why.
I did not show you my DNS Server IP by mistake. Scroll to the end to find out why.