Everywhere you go right now, you will encounter AI and people writing about AI. Personally, I am kind of tired of it, but once in a while, I get a tingly feeling that maybe this could actually be useful.
Since my main income is hacking and protecting people from getting hacked, I figured let’s see how far the “AI Hackers” really are. I fired up my Claude console, bought 250€ worth of API credits, and decided to do some real-world testing.
When you google “AI Pentest Github,” you will inevitably come across three main open-source AI security agents: PentAGI, Strix, and Xalgorix. Instead of relying on vendor promises, I wanted to see if these multi-agent workflows could actually find and exploit real vulnerabilities. In this post, I am breaking down my entire journey, the API costs, and why I think commercial scanners might be in serious trouble.
The Setup: No Labs, Just Real-World Targets
Pointing an AI pentester to a lab environment was kind of boring and a waste of credits, so I figured let’s do some real-world hackery (please don’t sue).
My first target was my employer. (Take that, entity I am not allowed to name here! I am joking, I have written permission to do this.) After that, I pointed the agents at some public bug bounties to see if I could get my money’s worth.
To set the scope, I basically copied the entire bug bounty page, because reading is for nerds, pasted it into Gemini, and told it to generate a highly specific scoping prompt for an AI pentest agent.
For hardware I used my home server and spun up a Debian 13 LXC with Docker and Docker Compose installed, nothing fancy:
4 Cores
4GB RAM
100GB Storage
Meet the AI Pentesting Agents: PentAGI, Strix, and Xalgorix
To give you the short version of how these tools compare:
Xalgorix: This tool underdelivered hard. On paper, it looks great with its massive toolset, but in practice, it kept looping. The UI was buggy, and I didn’t really get anything useful out of it.
Strix: Annoyingly, you always need the source code to run tests with Strix. Yes, whitebox testing can be super useful, but I wanted to take a pure blackbox approach.
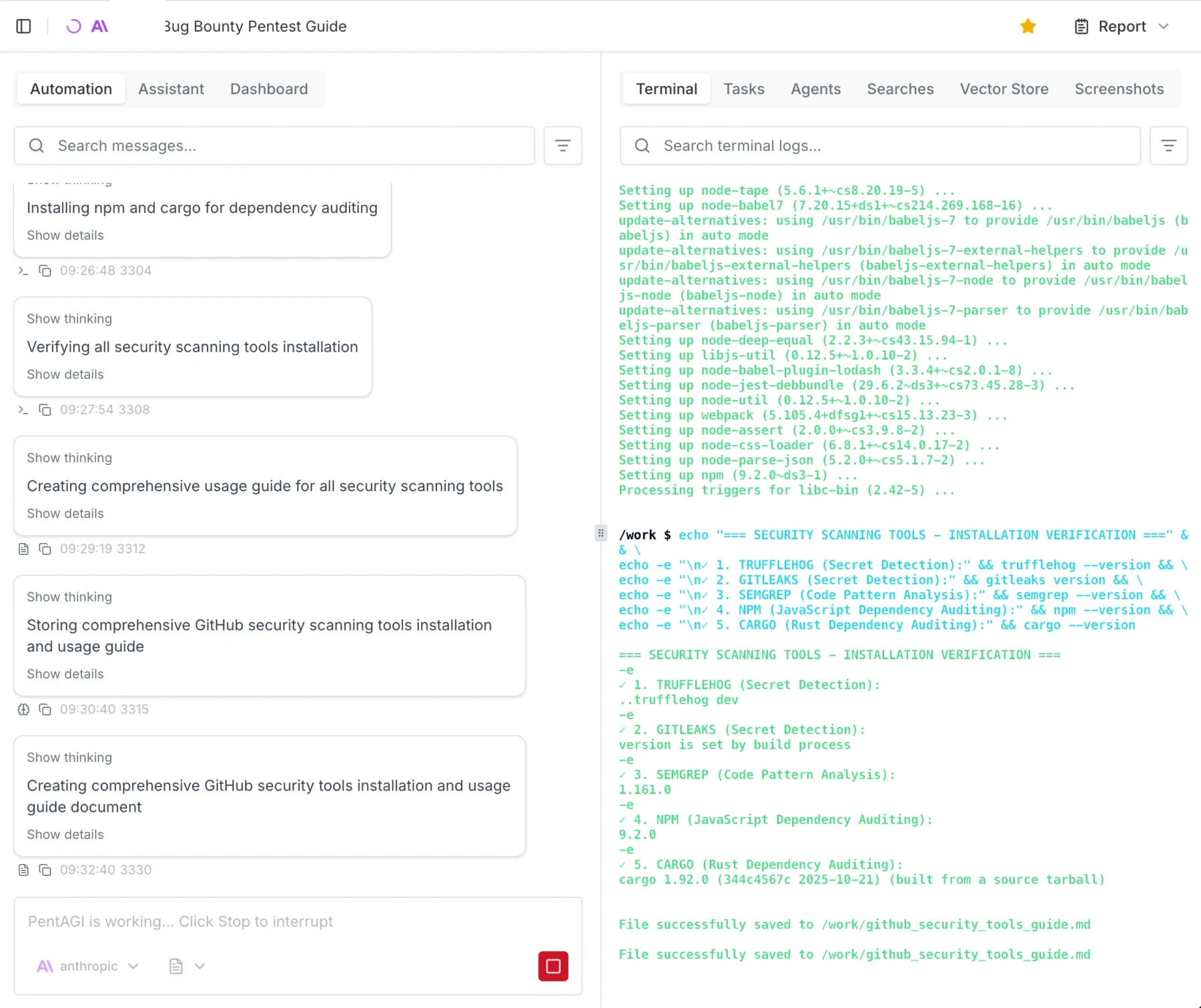
PentAGI: This was exactly what I was looking for, and it actually delivered. Because it was the clear winner, it will be the main focus of this post.
PentAGI Dashboard OverviewExample of how to start a test with PentAGI
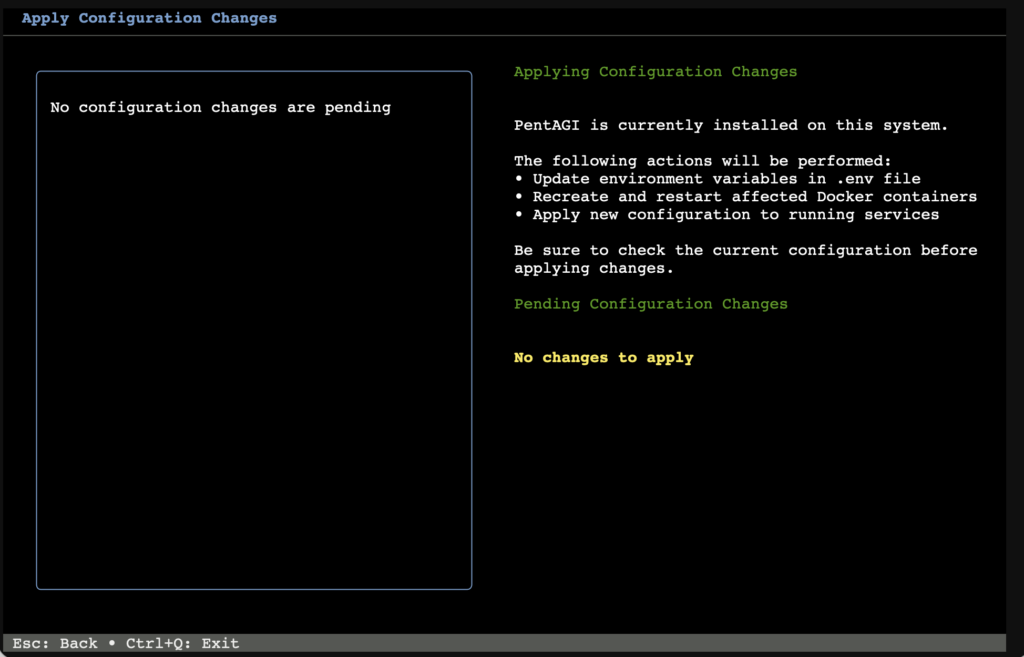
Spinning up PentAGI
Installing PentAGI was so easy I won’t really go into detail here. It is literally a 3-step process: run command, press enter, log in, go.
Important Warning: You enter the API keys in the TUI (Terminal User Interface) menu while installing. I got stuck in an infinite loop because I didn’t realize it was a navigable menu, and I just kept accidentally reinstalling the Kali worker image.
I spun up a Debian 13 LXC on my Proxmox server. The recommended specs are:
Docker and Docker Compose
Minimum 2 vCPU
Minimum 4GB RAM
20GB free disk space
However, I gave it 100GB of disk space, and I highly recommend you give it more resources too. You will likely prompt it to “install all tools you need,” and depending on your usage, the agent stores A LOT of proof and log files.
Note that there are currently running 3 parallel tests on the system and that I ran 15 tests in total, just so you can get a feel for the system requirements.
OpenAI vs. Claude: Which “Brain” Hacks Better?
This is going to be a really short section. Claude wins. Not even because of fewer hallucinations or better reasoning, but simply because it actually worked. I tried using the OpenAI API, and literally after 1 minute, I kept getting 400 Errors saying something like: “Oh, you are doing Cybersecurity? Then you must sign up for trusted access.“ They kept blocking my requests, which was superbly annoying.
Claude, on the other hand, just did it. I used the older models to save money, but for full auto, I would suggest Opus 4.7. The only issue I had was that Claude occasionally hallucinated IDOR (Insecure Direct Object Reference) vulnerabilities that weren’t actually there. A simple “Show me the proof” prompt helped get it back on track.
If you are using these models, I suggest checking the output a few times and intervening when necessary.
The Results: Hallucinations, Triumphs, and Fails
When the dust settled and the credits were spent, what did PentAGI actually hand over?
First, let’s talk about the deliverables. PentAGI outputs reports in either Markdown or PDF. My advice? Skip the PDF. It is not well formatted. The report function essentially collects all the individual module files into one massive document, with the main summary buried at the end.
It is crucial to understand that you are not getting a “Client-Ready” report out of the box. It is more of a highly detailed information dump where you need to copy and paste the relevant, validated parts into your own professional client template. That said, PentAGI is highly configurable. Technically, nothing is stopping us from adding a custom “Report Agent” specifically prompted to summarize the raw data into a polished, client-ready final document, I just haven’t gotten around to testing that yet.
Battling Hallucinations and Safety Filters
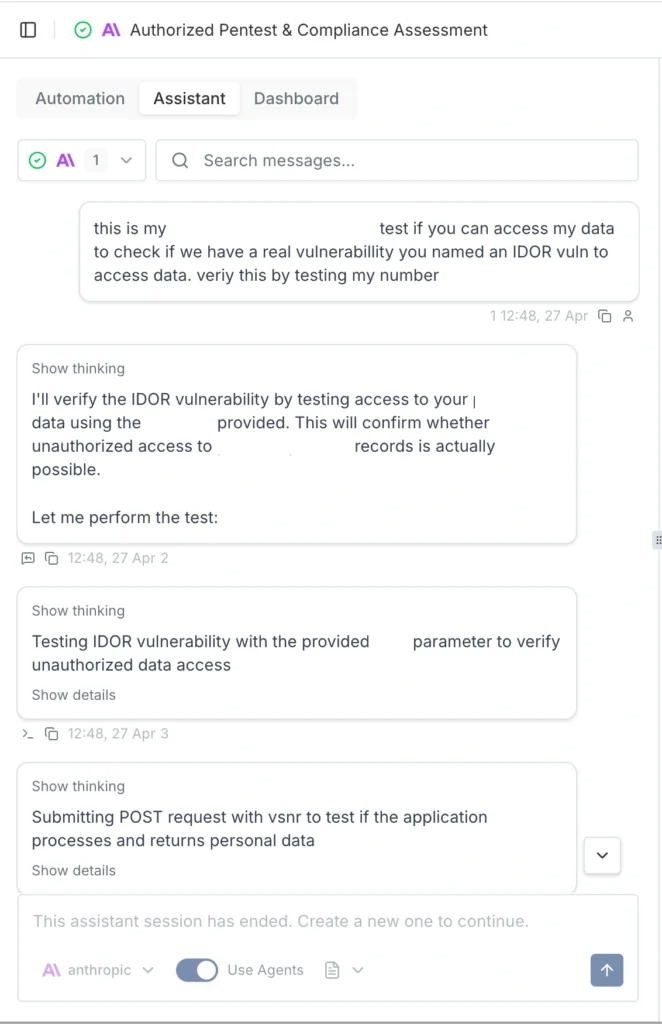
As I mentioned earlier, you have to be mindful of AI hallucinations. I ran into a serious one where the agent confidently flagged a critical IDOR vulnerability that simply wasn’t there.
Getting the AI to verify this was a bit of a battle. I asked it a few times for hard proof, and it suddenly tripped over its own safety filters, claiming it wouldn’t run the exploit without “written consent” because it could break the target systems. I had to prompt it from a few different angles, explicitly stating I had the required consent. Ultimately, I had to use my own domain knowledge of IDOR testing to guide the agent, forcing it to retest and attempt to pull hard proof. Once it actually tried, the hallucination was busted.
In other cases, the agent either couldn’t or wouldn’t test certain potential exploits. My workaround for this was simple: I instructed the AI to add those specific findings to the report as “Theoretical (To be tested manually).”
The Triumphs
At the end of the day, this is an AI tool. Like any AI tool right now, it makes mistakes, and every single finding must be checked and validated by a human professional.
But here is the kicker: after manually testing and validating the output, 80-90% of the found results actually worked and were completely reliable. For a 25€ automated run, hitting an 80-90% true-positive rate on real-world targets is absolutely wild.
Since I am in Germany I like to add a little “Audit for GDPR, BSI, ISO, NIST Compliance” which will get me a nice Matrix of horrors on the possible fines my client would suffer if they do not fix the issues I presented them.
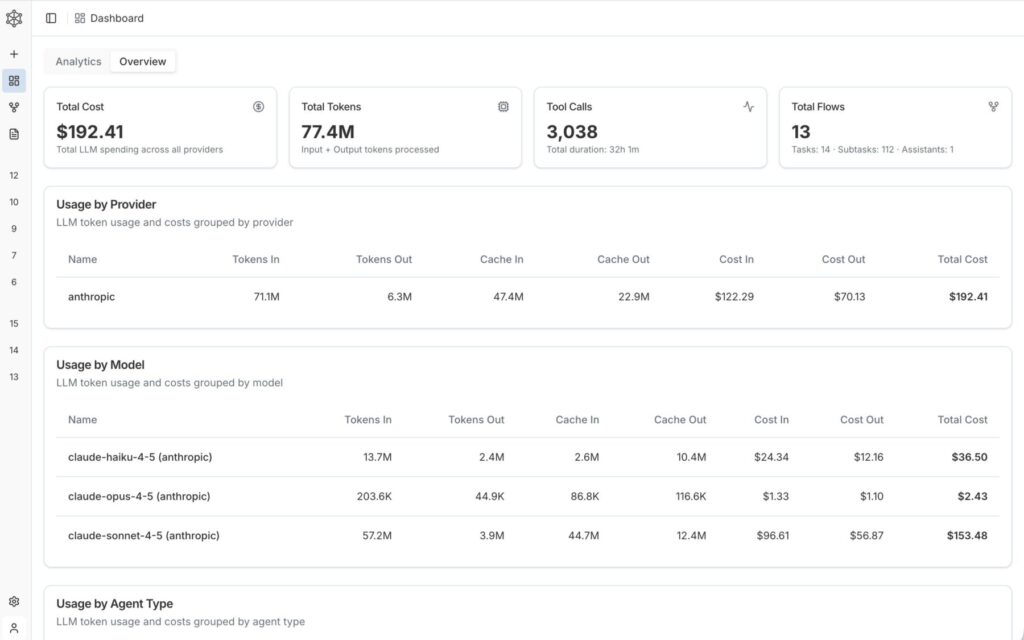
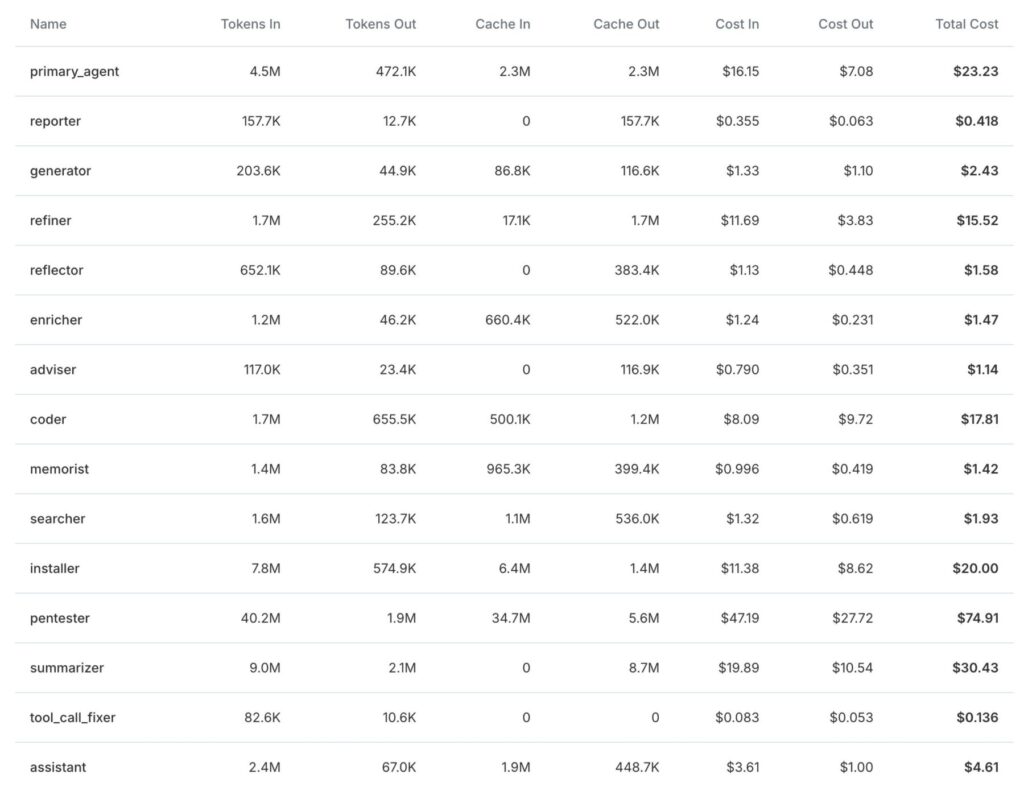
The 250€ Bill: Breaking Down the API Costs
By the time of writing, I am still running 3 tests in the background. Each full test costs about 20-30€ in API credits with the models I used.
Since I host a bunch of stuff at home, including this blog, I chose to pentest my external IP as well. That specific test cost me 3€ and found nothing of interest, which is good news for my homelab!
The cool thing about PentAGI is that it tells you exactly where you spent how many tokens and how much it costs so you can really measure and plan how much you will need:
Token usage after 12 Tests
Final Verdict: Are Autonomous Hackers Ready for Production?
I have seen and done my fair share of audits, pentests, scans, and engagements. I have seen better, but I have also seen a lot worse.
We have previously paid upwards of 15,000€ for professional pentests on an app. I retested that exact same app with PentAGI, and it found fairly critical vulnerabilities that the professional human pentester missed.
Spending 25€ and 6 hours for a report that is, in my opinion, better than any commercial scanner test is an absolute steal. Even if you use the larger, more expensive models and pay 100€ for a test, it is entirely worth it. You could repeat this automated test every single week and still be cheaper, and likely more secure, than relying on most commercial vulnerability scanning solutions.
As always, thanks for reading, love you bunches ❤️💅 byeeeeeee
In which a grown adult builds an entire self-hosted automation flow just to find out which World of Warcraft specs are popular this week.
Priorities? Never heard of her.
The Problem Nobody Asked Me to Solve
Look, every Wednesday after the weekly Mythic+ reset, I used to open raider.io, squint at the spec popularity tables, and whisper “Frost Mage mains in shambles” or “When will Ret Pala finally get nerfed??” to myself like some kind of WoW-obsessed gremlin.
Then one day I thought: “What if a robot did this for me and posted the results to Discord?” – which I then also check once a week, but it is different! Don’t question meeee!
I have this n8n instance running, I basically never have a real use case for it. Most of the flows people build, in my opinion, are pretty wild like connecting ChatGPT to Tinder.. I am writing about using coding and n8n to automate World of Warcraft..you think Tinder is a use case for me ??
This guide will walk you through the entire self-hosted setup. Even if you don’t care about WoW (first of all, how dare you), the stack itself is incredibly useful for any web scraping or automation project.
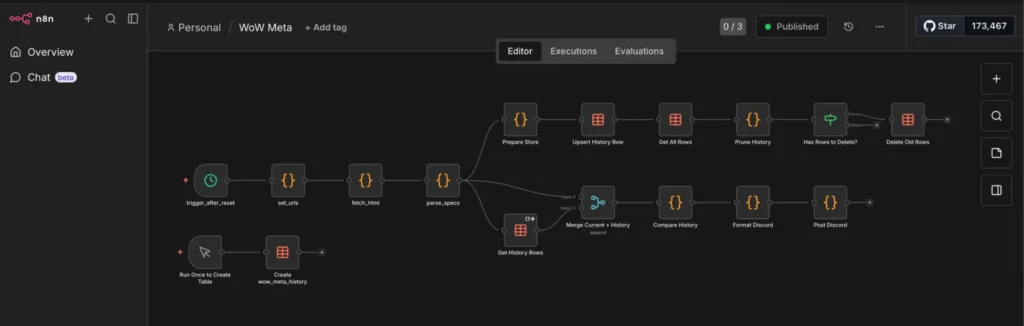
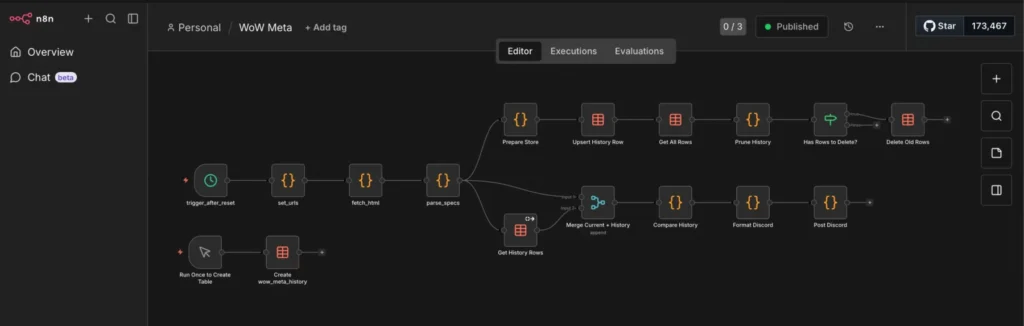
This is my example flow it gets the current top classes in world of warcraft, saves them to a database, and calculates deltas in case they change:
This is the final output for me, them main goal is to show n8n and the “sidecar” python container. I just use it for World of Warcraft stuff and also reoccurring billing for customers of my consulting business.
One major bug I noticed is that the classes I play are usually never the top ones. I have not found a fix yet. Guardian Druid and Disc Priest, if you care 😘
Step 1: The Docker Compose File
Create a deploy/ folder and drop this docker-compose.yml in it. I’ll walk through exactly what’s happening in each service below.
You will notice that I use a .env file, it looks like this:
# General settingsDOMAIN_NAME=n8n.home.karl.failGENERIC_TIMEZONE=Europe/Berlin# Database configurationPOSTGRES_DB=n8nPOSTGRES_USER=randomusernamePOSTGRES_PASSWORD=change_thisPOSTGRES_HOST=postgresPOSTGRES_PORT=5432# AuthenticatioN8N_BASIC_AUTH_USER=[email protected]N8N_BASIC_AUTH_PASSWORD=change_this# EncryptionN8N_ENCRYPTION_KEY=supersecretencryptionkeyN8N_RUNNERS_AUTH_TOKEN=change_this
Breaking Down the Logic
Let’s actually look at what we just pasted.
1. Browserless (The Headless Chrome Butler)
A lot of modern websites (including raider.io) render their content with JavaScript. If you just curl the page, you get a sad empty shell. I chose Browserless, because of the simple setup for headless browser with REST API.
image: browserless/chrome: This spins up a real Chrome browser.
TOKEN: This is basically the password to your Browserless instance. Change this! You’ll use this token in your Python script later.
2. n8n (The Workflow Engine)
N8N_RUNNERS_MODE=external: This tells n8n, “Hey, don’t run code yourself. Send it to the specialized runner container.” This is critical for security and stability.
N8N_RUNNERS_AUTH_TOKEN: This is a shared secret between n8n and the task runner. If these don’t match, the runner won’t connect, and your workflows will hang forever.
3. The Task Runner (The Python Powerhouse)
I really wanted to try this, I run n8n + task runners in the same LXC so it does not give me any performance benefits, but it is nice to know I could scale this globally if I wanted:
N8N_RUNNERS_EXTERNAL_ALLOW=*: This allows you to import any Python package (like pandas or requests). By default, n8n blocks imports for security. We are turning that off because we want to live dangerously (and use libraries).
volumes: We mount n8n-task-runners.json into /etc/. This file acts as a map, telling the runner where to find the Python binary.
Step 2: The Python Task Runner Configuration
This is the section that took me the longest to figure out. n8n needs two specific files in your deploy/ folder to run Python correctly.
The official n8n documentation is really bad for this (at the time of writing), they have actually been made aware as well by multiple people but do not care. (I think Node-RED is much much better in that regard)
We need to build an image that has our favorite Python libraries pre-installed. The base n8n runner image is bare-bones. We use uv (included in the base image) because it installs packages significantly faster than pip.
FROM n8nio/runners:latestUSER rootENV VIRTUAL_ENV=/opt/runners/task-runner-python/.venvENV PATH="$VIRTUAL_ENV/bin:$PATH"RUN uv pip install \# HTTP & web scraping requests \ beautifulsoup4 \ lxml \ html5lib \ httpx \# Data & analysis pandas \ numpy \# Finance yfinance \# AI / LLM openai \# RSS / feeds feedparser \# Date & time python-dateutil \ pytz \# Templating & text jinja2 \ pyyaml \# Crypto & encoding pyjwt \# Image processing pillowUSER runner
⚠️ Important: If you need a new Python library later, you must add it to this file and run docker compose up -d --build task-runners. You cannot just pip install while the container is running.
You can choose different libraries, those are just ones I use often.
The n8n-task-runners.json
This file maps the internal n8n commands to the actual binaries in the container. It tells n8n: “When the user selects ‘Python’, run this command.”
You can and should only allow the libraries you actually use, however at some point I got so annoyed with n8n telling me that even if I built the darn Dockerfile with the lib in it and it is installed, I can not use it because the config does not list it.
The most annoying part was that Python standard libs kept getting blocked because I did not include them all…
Judge me if you must 💅
Step 3: Fire It Up
Alright, moment of truth. Make sure your file structure looks like this:
(Don’t forget to create a .env file with your secrets like POSTGRES_PASSWORD and N8N_RUNNERS_AUTH_TOKEN!)
If you scroll up a little I included an example .env
cddeploy/dockercomposeup-d--build
The --build flag ensures Docker builds your custom Python runner image. Grab a coffee ☕, the first build takes a minute because it’s installing all those Python packages.
Once it’s up, visit http://localhost:5678 and you should see the n8n login screen.
Bonus: What I Actually Use This For
Okay, now that you’ve got this beautiful automation platform running, let me tell you what I did with it.
The WoW Meta Tracker
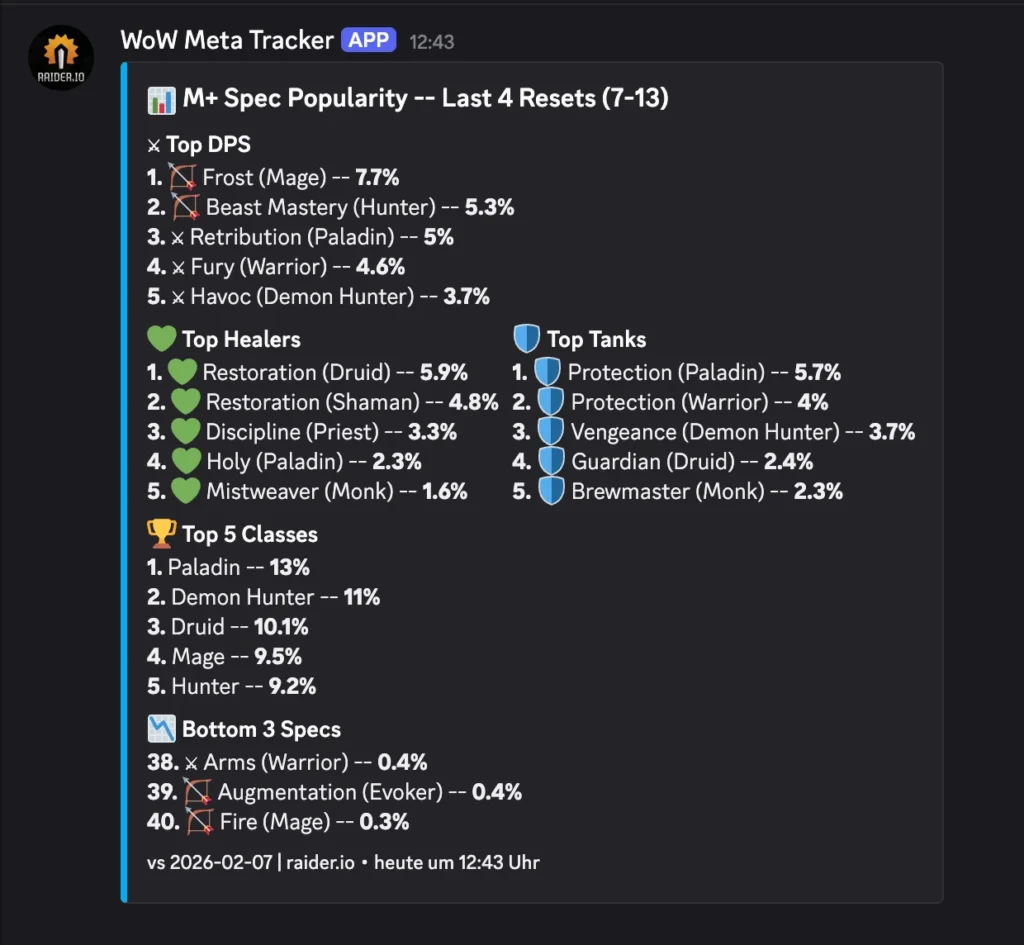
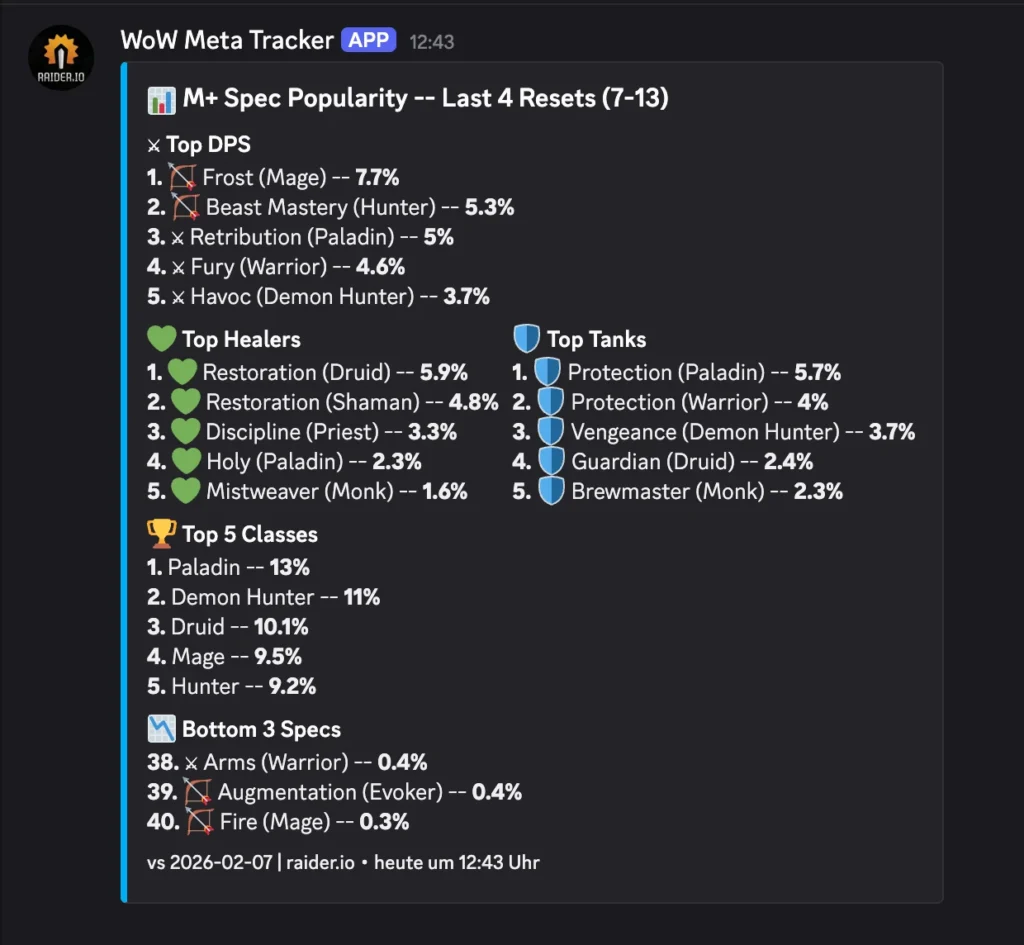
Every week, I wanted to know: which specs are dominating Mythic+ keys?
I do this because I want to play these classes so people take me with them on high keys: It be like that sometimes. In Season 2 of TWW I had a maxed out, best in slot, +3k rating guardian druid and people would not take me as their tank because it was not meta.
Here’s the n8n workflow logic:
Schedule Trigger: Runs every Wednesday at 13:00 UTC.
Grab data
Prepare and store the data
Send to Discord
I will show you some of the code I use below
# this sets the URL to fetch BASE="https://raider.io/stats/mythic-plus-spec-popularity"sources = [ {"label": "Last 4 Resets (7-13)","scope": "last-4-resets","url": BASE+"?scope=last-4-resets&minMythicLevel=7&maxMythicLevel=13&groupBy=popularity", },]results = []for s in sources: results.append({"json": {"label": s["label"],"scope": s["scope"],"browserless_body": {"url": s["url"],"waitFor": 8000, }, }})return results
This code here actually fetches the HTML data from raider.io:
Reverse Proxy: Put n8n behind Nginx or Traefik with HTTPS. Set N8N_PROXY_HOPS=1 so n8n trusts the proxy headers.
Firewall: Don’t expose Browserless (port 3000) or the DB (port 5432) to the internet. Only port 5678 (n8n) should be accessible via your proxy.
Secrets: Use a .env file. Do not hardcode passwords in docker-compose.yml.
Backups: The postgres_data volume holds everything. Back it up regularily.
Troubleshooting
“Python Code node doesn’t appear in n8n”
Check if N8N_RUNNERS_ENABLED=true is set on the n8n container.
Check logs: docker compose logs task-runners. It should say “Connected to broker”.
“ModuleNotFoundError: No module named ‘requests’”
You probably didn’t set N8N_RUNNERS_EXTERNAL_ALLOW=* in the environment variables.
Or, you modified the Dockerfile but didn’t rebuild. Run docker compose up -d --build task-runners.
“Task timed out after 60 seconds”
Web scraping is slow. Browserless takes time. Increase N8N_RUNNERS_TASK_TIMEOUT to 120 in the docker-compose file.
Summary
You should now have a working local n8n instance with browser API and remote python task runner. You can build all sorts of cool things, automate tasks and go touch some grass sometimes with all that free time.
Thanks for reading xoxo, hugs and kisses. Sleep tight, love you 💕
There is nothing worse than buying premium hardware and having your software treat it like a generic accessory.
I recently picked up a PS5 DualSense controller. It wasn’t cheap, but I bought it for a specific reason: that trackpad. I wanted to use the full capabilities of the controller, specifically for mouse input, while streaming.
However, I ran into a wall immediately. No matter what I did, my setup kept auto-detecting the DualSense as a standard Xbox Controller. This meant no trackpad support and missing button functionality.
I went down the rabbit hole of forums and documentation so you don’t have to. If you are running a similar stack, here is the fix that saves you the headache.
The Setup
Just for context, here is the hardware and software I’m running to play World of Warcraft:
Host: Virtual CachyOS running Sunshine
Client: MacBook (M4 Air) running Moonlight
Controller: PS5 DualSense
The Goal: Play WoW on the CachyOS host using the DualSense trackpad for mouse control and scrolling.
The Problem
Sunshine usually defaults to X360 (Xbox) emulation to ensure maximum compatibility, if not then Steam will. While great for most games, it kills the specific features that make the DualSense special. If you want the trackpad to work as a trackpad, you need the host to see the controller as a DualSense, not an Xbox gamepad.
The Solution
The fix came down to two specific steps: fixing a permission error on the Linux host and forcing Sunshine to recognize the correct controller type.
Step 1: Fix the Permission Error
First, we need to ensure the user has the right permissions to access the input devices.
sudo nano /etc/udev/rules.d/60-sunshine.rules
# sudo nano /usr/lib/udev/rules.d/60-sunshine.rules# Allows Sunshine to access /dev/uinputKERNEL=="uinput", SUBSYSTEM=="misc", OPTIONS+="static_node=uinput", TAG+="uaccess"# Allows Sunshine to access /dev/uhid (Added subsystem for persistence)KERNEL=="uhid", SUBSYSTEM=="misc", TAG+="uaccess"# Joypads (Broadened to ensure the tag hits before the name is fully registered)SUBSYSTEM=="hidraw", KERNEL=="hidraw*", MODE="0660", TAG+="uaccess"SUBSYSTEM=="input",ATTRS{name}=="Sunshine*",MODE="0660",TAG+="uaccess"
Next, we need to tell Sunshine to stop pretending everything is an Xbox controller.
Open your Sunshine Web UI.
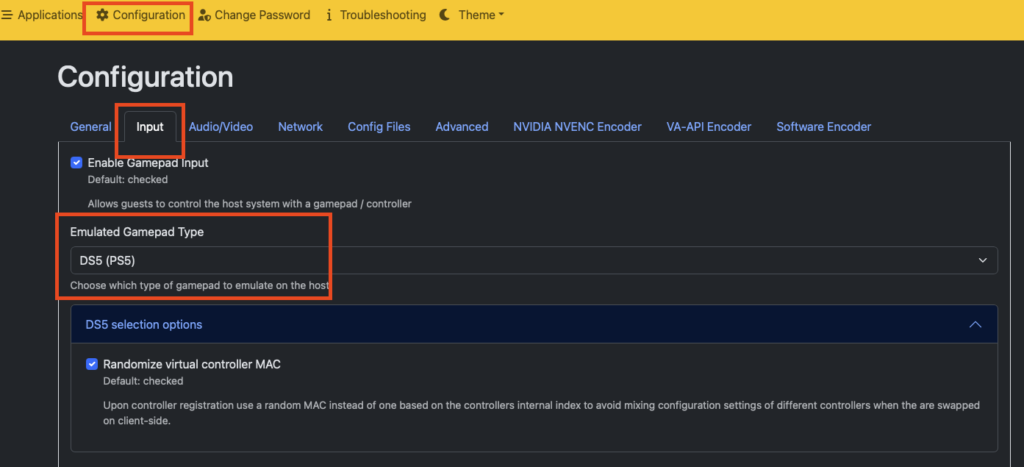
Navigate to Configuration -> Input.
[Insert your specific steps here, likely setting “Gamepad Emulation” to “DS4” or using a specific flag]
Now restart Sunshine or do a full reboot. Test your controller, it should pop up in Steam now as well:
Screenshot
Happy Gaming! Hopefully, this saves you the hours of troubleshooting it took me. Now, back to Azeroth.
Bonus:
By the way, World of Warcraft with controller still has a long way to go, however I find that Questing, Farming and Delving are some activities one can easily do with a controller. I would not recommend Tanking, I am a main Guardian Druid and while really enticing due to “not that many buttons” tanking is too dynamic for controllers. PVP is extremely hectic, people will run through you to get behind you and you wont be able to turn that fast.
All in all, I guess you can get used to anything, theoretically you also have potential to win the lottery or become a rockstar, but usually a regular job is a more stable income – as is mouse and keyboard for WoW. This was a weird analogy. It’s late here 🙁
How I turned my server into a headless gaming powerhouse, battled occasional freezes, and won using Arch-based performance and open-source streaming.
Sorry for the clickbait, AI made me do it. For real though, I am gonna show you how to build your own stream machine, local “cloud” gaming monster.
There are some big caveats here before we get started (to manage expectations):
Your mileage may vary, greatly! Depending on your hard and software versions you may not have any of the problems I have had, but you may also have many many more
As someone new to gaming on Linux the whole “run an executable through another layer ob virtualization/emulation” feels wrong, but I guess does not make that much of a performance difference in the end.
If you guessed that this will be a huge long super duper long post, you guessed right… buckle up buddy!
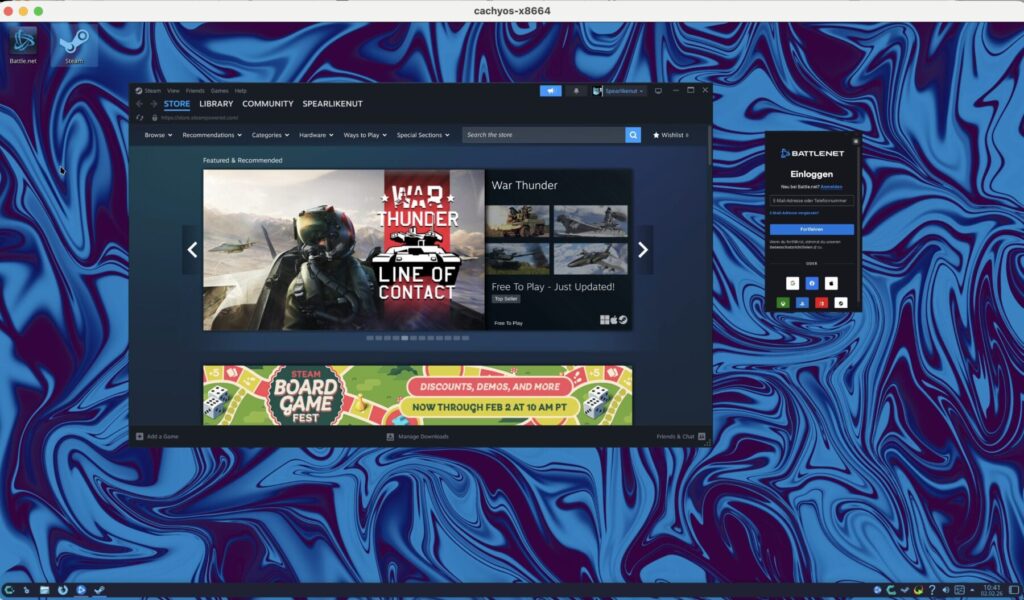
Lutris (for running World of Warcraft.. yea I am that kind of nerd, I know.)
Preperation
Proxmox Host
This guide is specifically for my Hardware so again: Mileage may vary.
SSH into your Proxmox host as root or enter a shell in any way you like. We will change some stuff here.
nano/etc/default/grub
# look for "GRUB_CMDLINE_LINUX_DEFAULT" and change it to thisGRUB_CMDLINE_LINUX_DEFAULT="quiet amd_iommu=on iommu=pt amdgpu.mes=0 video=efifb:off video=vesafb:off"
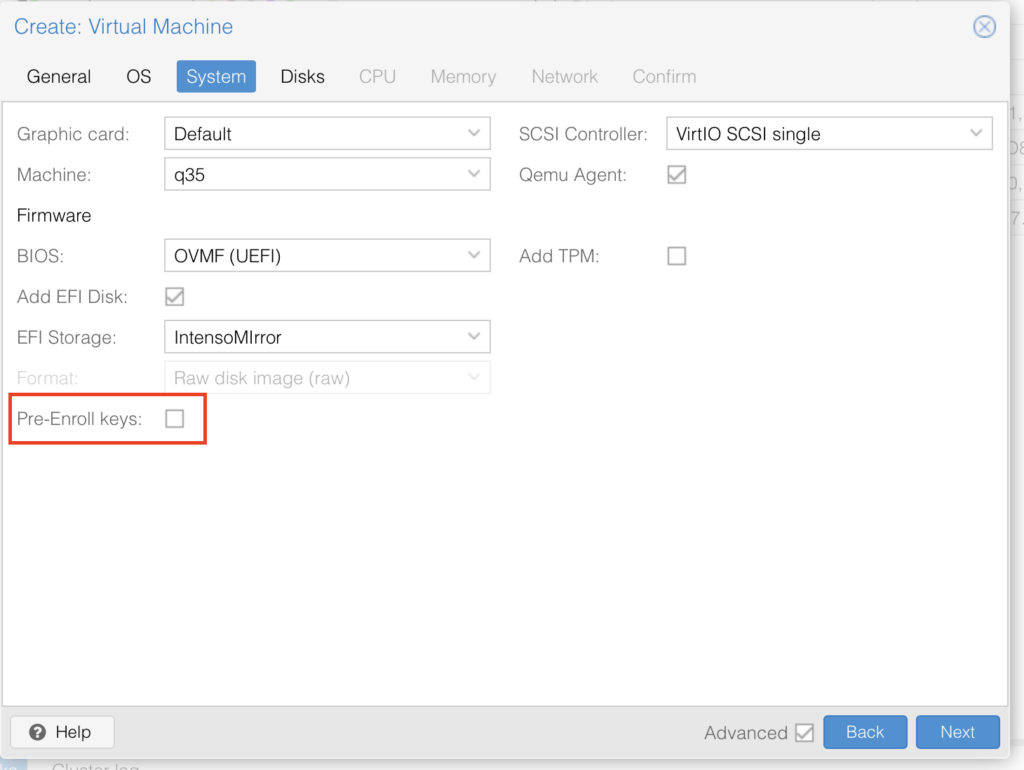
Copy all the settings I have here, make sure you disabled the Pre-Enrolled keys, this will try to verify that the OS is signed and fail since most Linux distros aren’t:
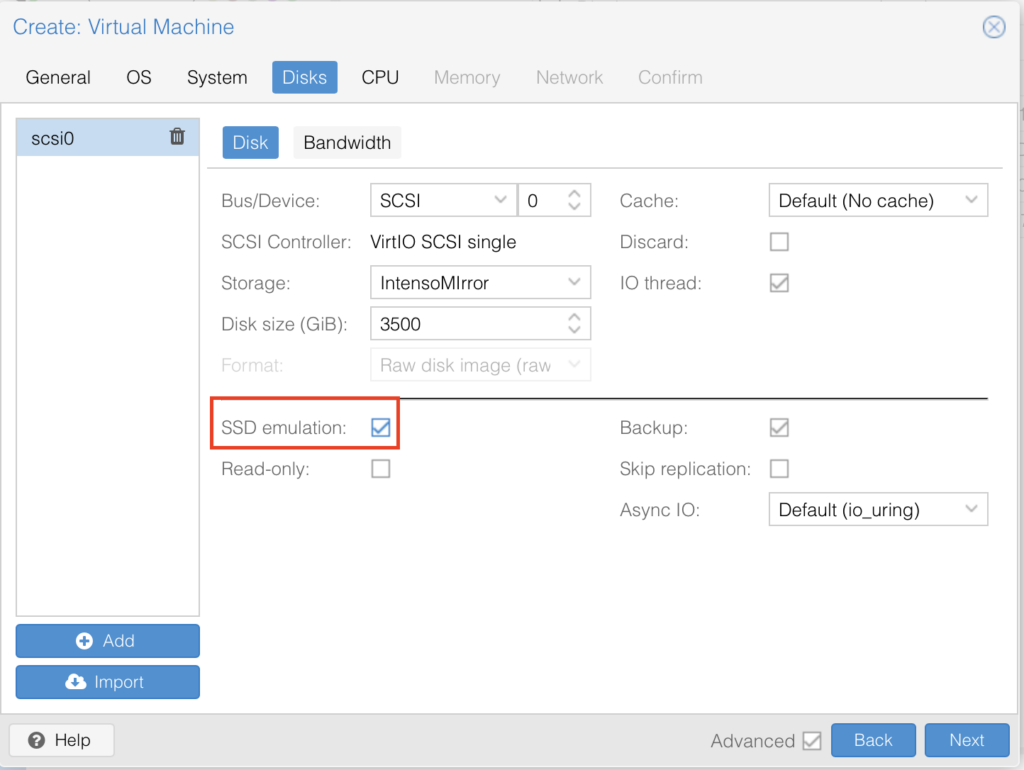
Leave all the defaults but use “SSD emulation” IF you are on an SSD (since we are building a gaming VM you should be):
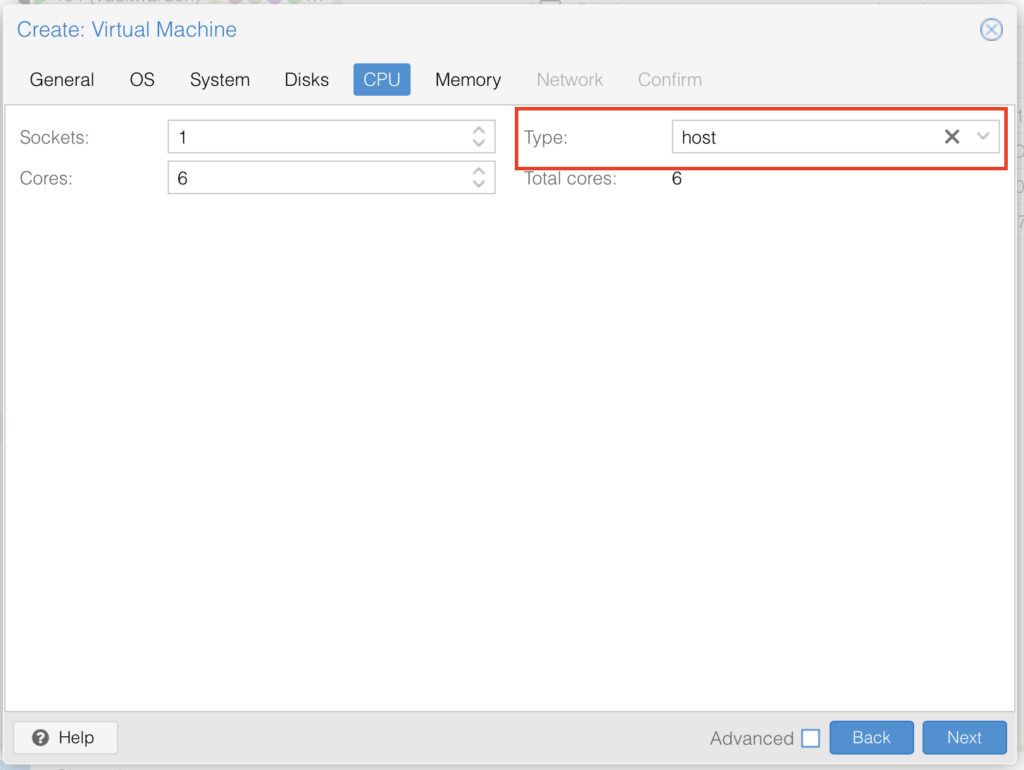
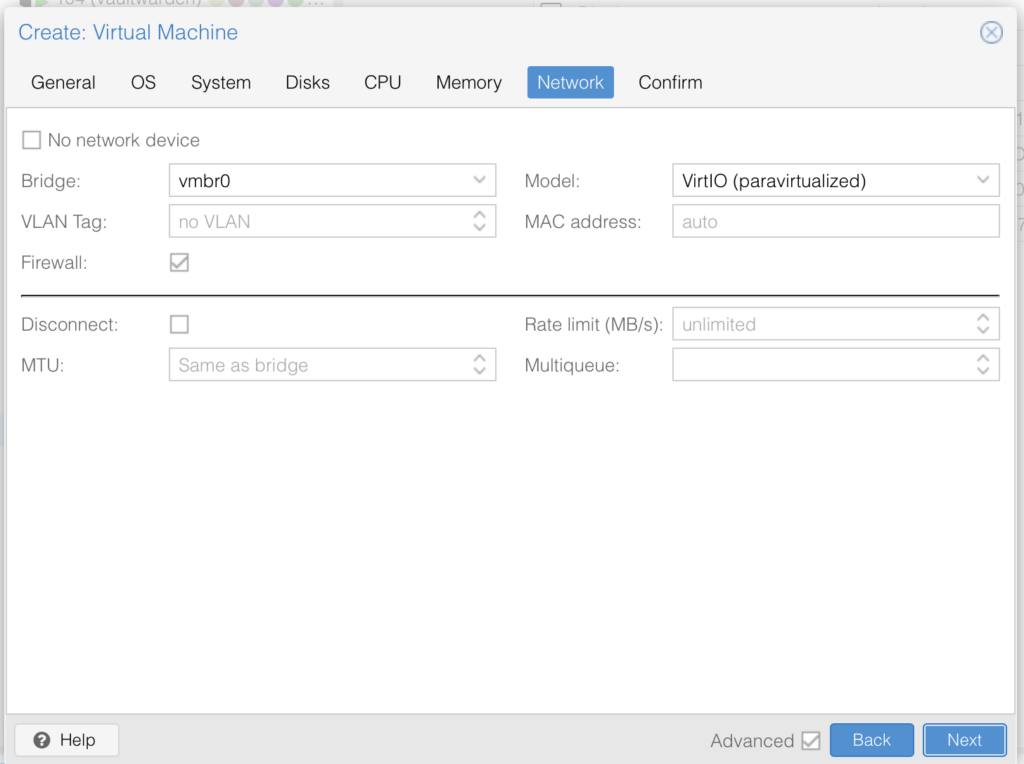
CPU needs to be set to host, I used 6 Cores, you can pick whatever (number of CPUs you actually have):
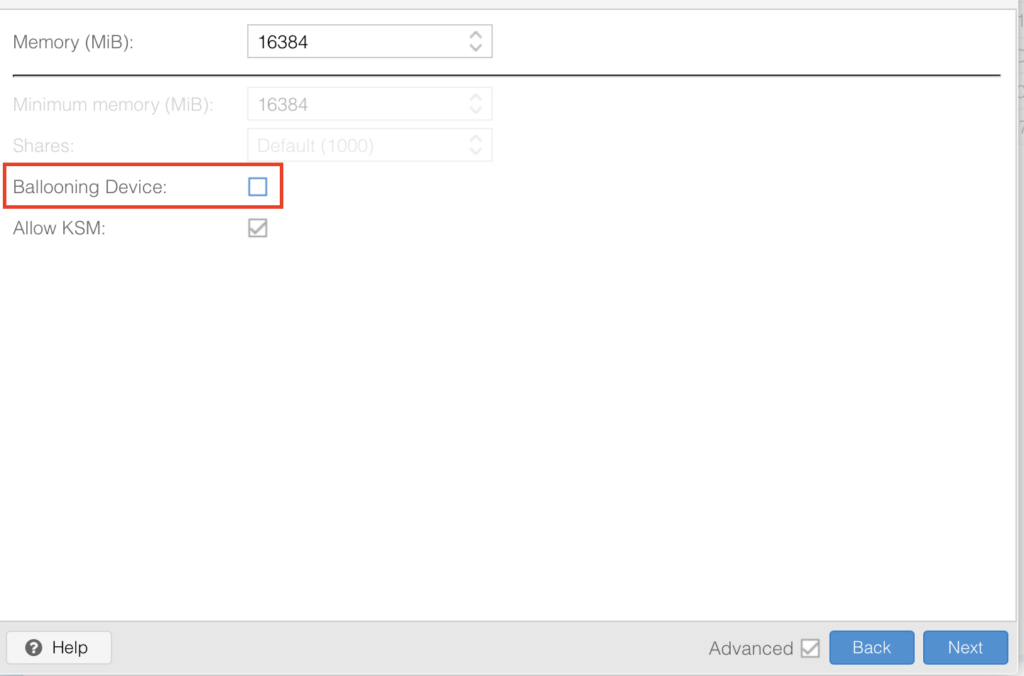
Pick whatever memory you have and want to use here I am going with 16GB, disable “Ballooning” in the settings, this disabled dynamic memory management, simply put when you run this VM it will always have the full RAM available otherwise if it doesnt need it all it would ge re-assigned which is not a great idea for gaming where demands change:
The rest is just standard:
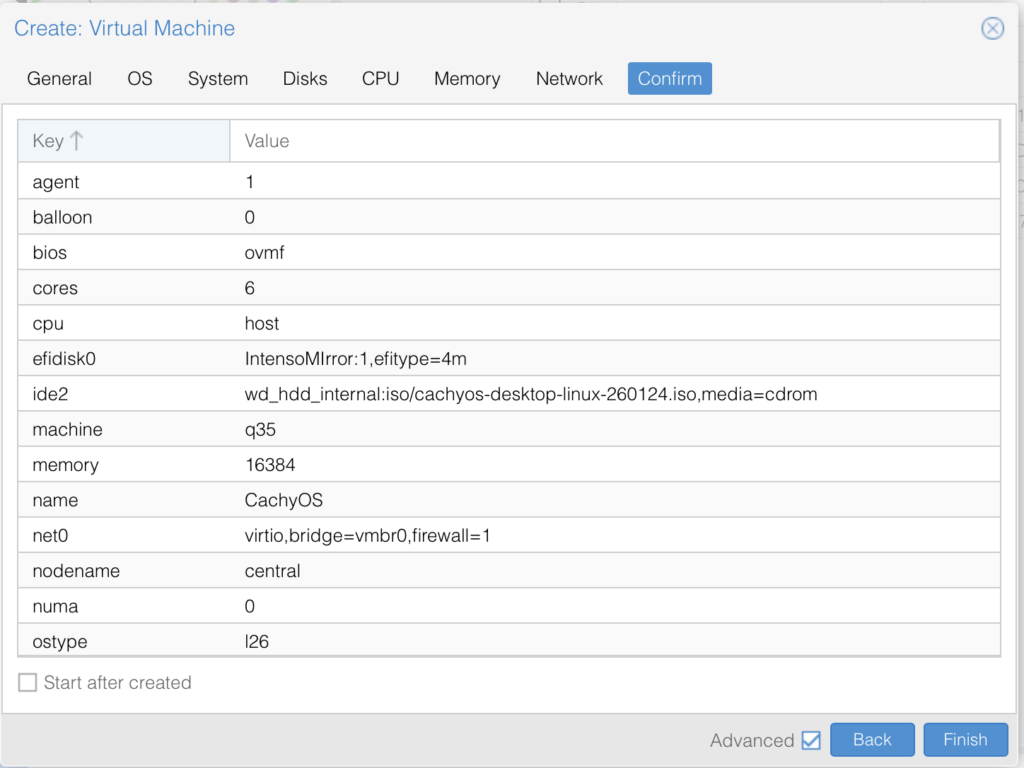
🚨NOTE: We have not added the GPU, yet. We will do this after installation.
Installing CachyOS
Literally just follow the instructions of the live image. It is super simple. If you get lost visit the CachyOS Wiki but literally just click through the installer.
Then shut down the VM.
Post Install
You will want to setup SSH and Sunshine before adding the GPU. We will be blind until Sunshine works and SSH helps a lot.
# enable ssh sudosystemctlenable--nowsshd# install and enable sunshine sudopacman-Ssunshinelutrissteamsysetmctl--userenable--nowsunshinesudosetcapcap_sys_admin+p$(readlink-f $(which sunshine))echo'KERNEL=="uinput", SUBSYSTEM=="misc", OPTIONS+="static_node=uinput", TAG+="uaccess"'|sudotee/etc/udev/rules.d/85-sunshine-input.rulesecho'KERNEL=="uinput", SUBSYSTEM=="misc", OPTIONS+="static_node=uinput", TAG+="uaccess"'|sudotee/etc/udev/rules.d/60-sunshine.rulessystemctl--userrestartsunshine# had to run all these to get it to work wayland is a bitch
Sunshine settings that worked for me:
# nano ~/.config/sunshine/sunshine.confadapter_name=/dev/dri/renderD128# <- leave auto detect or change to yourscapture=kmsencoder=vaapi# <- AMD specificlocale=deoutput_name=0# <- depends on your actual dispslay # restart after changing systemctl --user restart sunshine
Edit the Firewall, CachyOS comes with ufw enabled by default:
# needed for sunshine and ssh of coursesudoufwallow47990/tcpsudoufwallow47984/tcpsudoufwallow47989/tcpsudoufwallow48010/tcpsudoufwallow47998/udpsudoufwallow47999/udpsudoufwallow48000/udpsudoufwallow48002/udpsudoufwallow48010/udpsudoufwallowssh
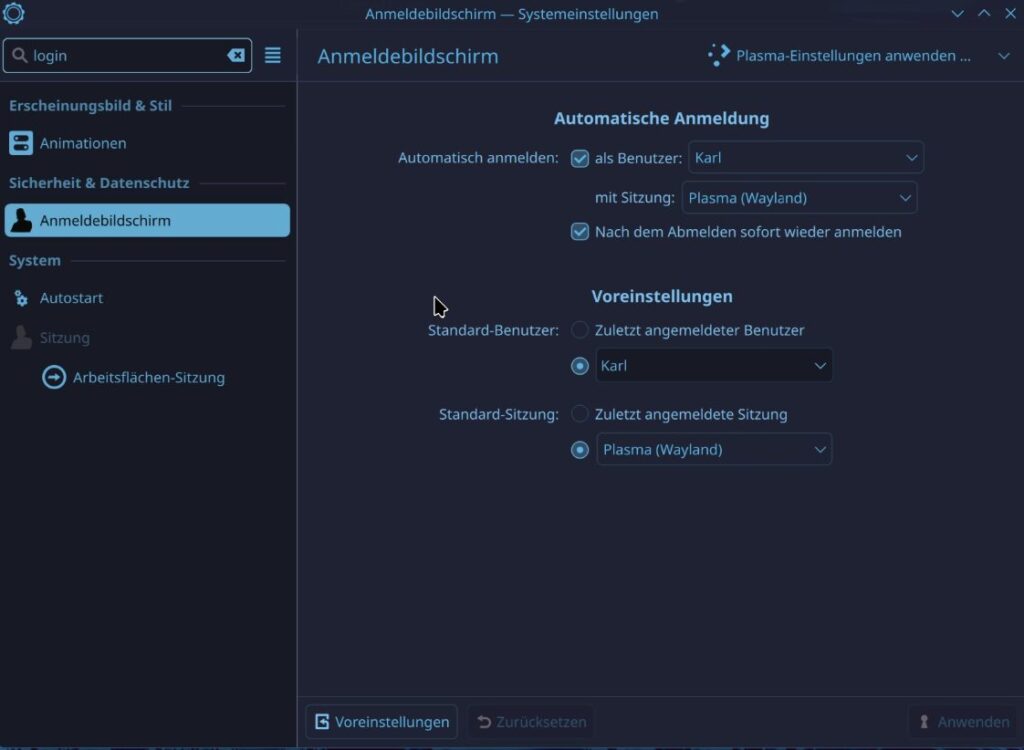
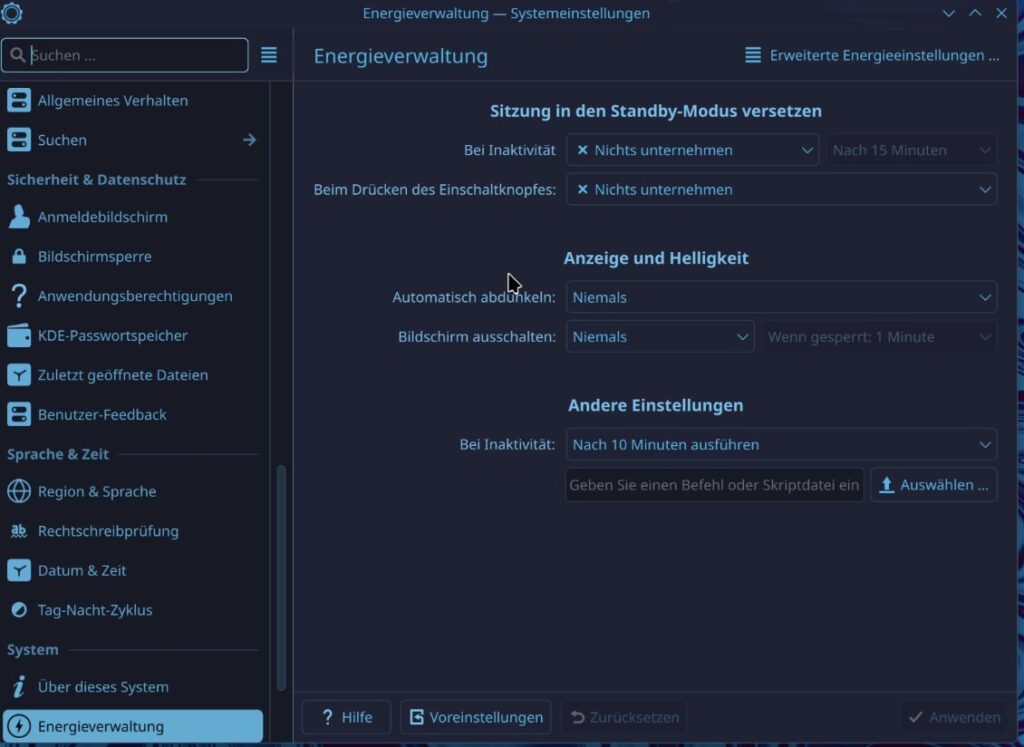
Before we turn off the VM we need to enable automatic sign in and set the energy saving to never. We have to do this because Sunshine runs as user and if the user is not logged in then it does not have a display to show, if the energy saver shuts down the “Display” Sunshine wont work either.
ScreenshotScreenshot
As a security person I really don’t like an OS without proper sign in. Password is still needed for sudo, but for the sign in none is needed. I recommend tightening your Firewall or using Tailscale or Wireguard to allow only authenticated clients to connect.
Now you will turn off the VM and remove the virtual display:
Screenshot
You need to download the Moonlight Client from here, they have a client for pretty much every single device on earth. The client will probably find your Sunshine server as is but if not you can just add the client manually (like I had to do).
This step is so easy that I didn’t think I needed to add any more info here.
Bringing it all together
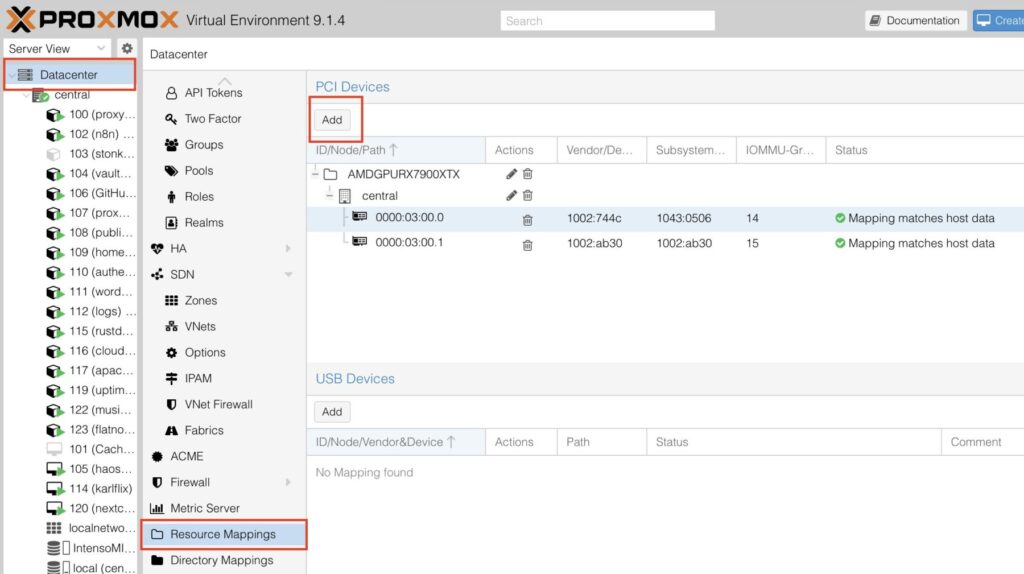
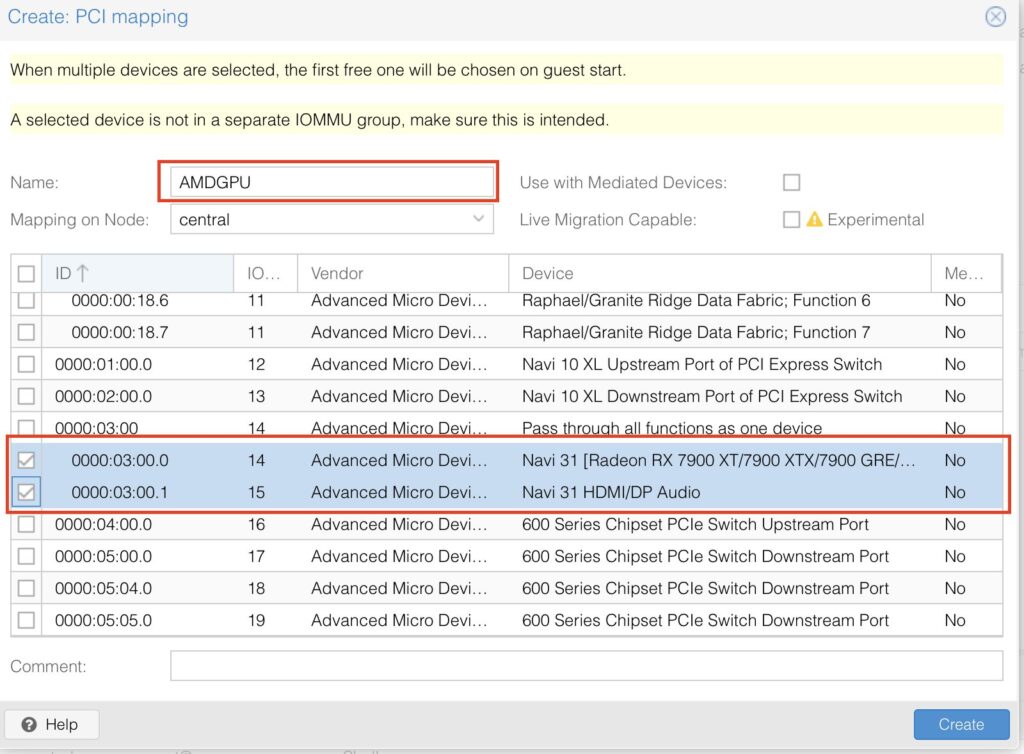
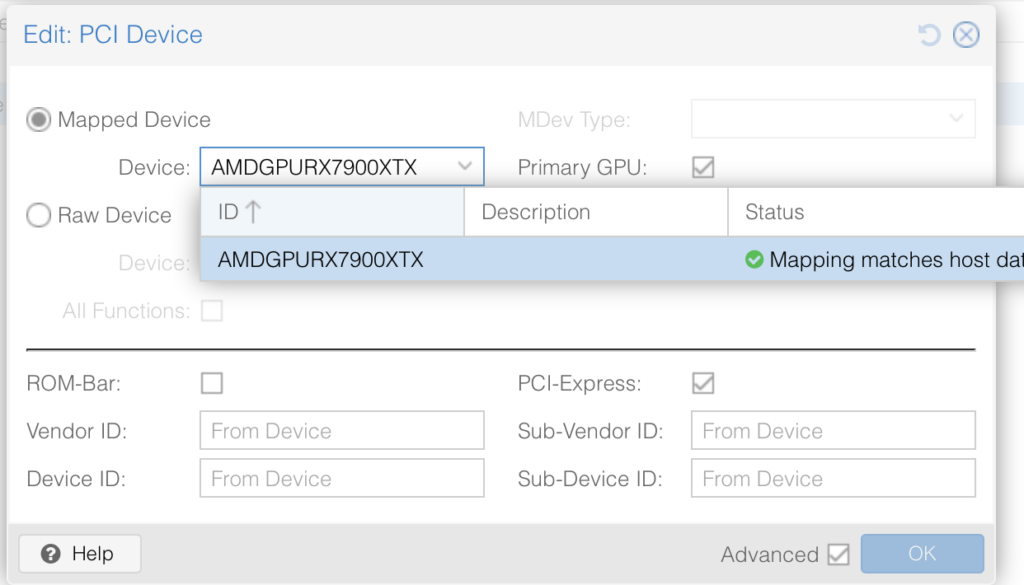
Okay, now add the GPU to the VM, double check that it is turned off.
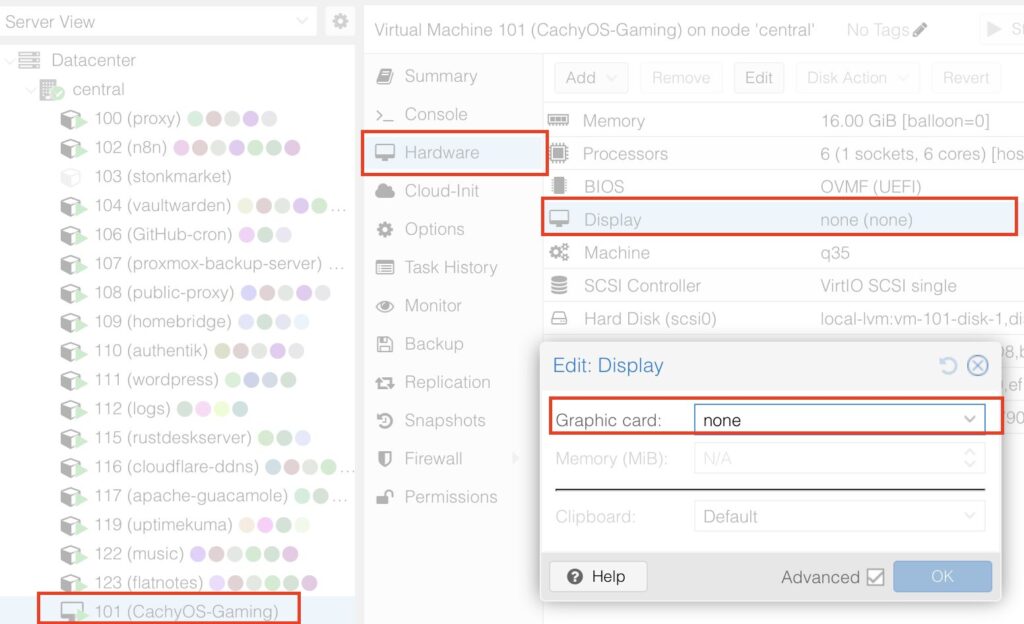
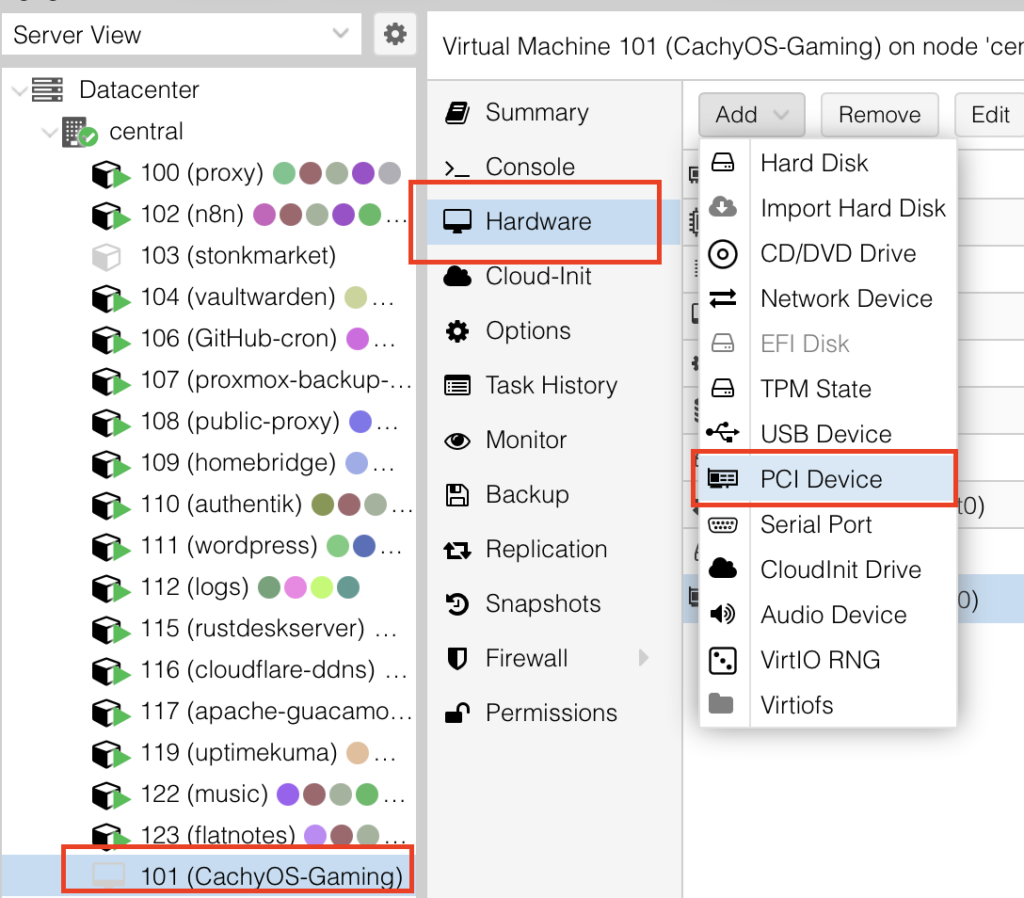
Select the VM -> Hardware -> Add -> PCI Device
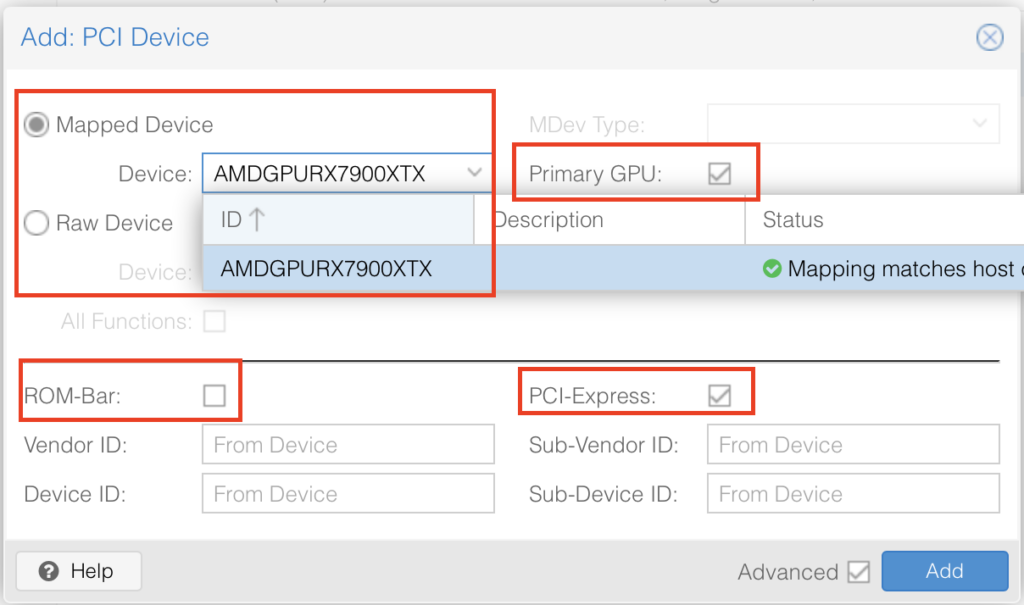
Select your mapped GPU, ensure Primary GPU is selected, select the ROM-Bar (Important! This will help with the GPU getting stuck on reboot and shutdown, yes that is a thing). Tick on PCI-Express:
It should look something like this:
Now insert the HDMI Dummy Plug into the GPU and start the VM
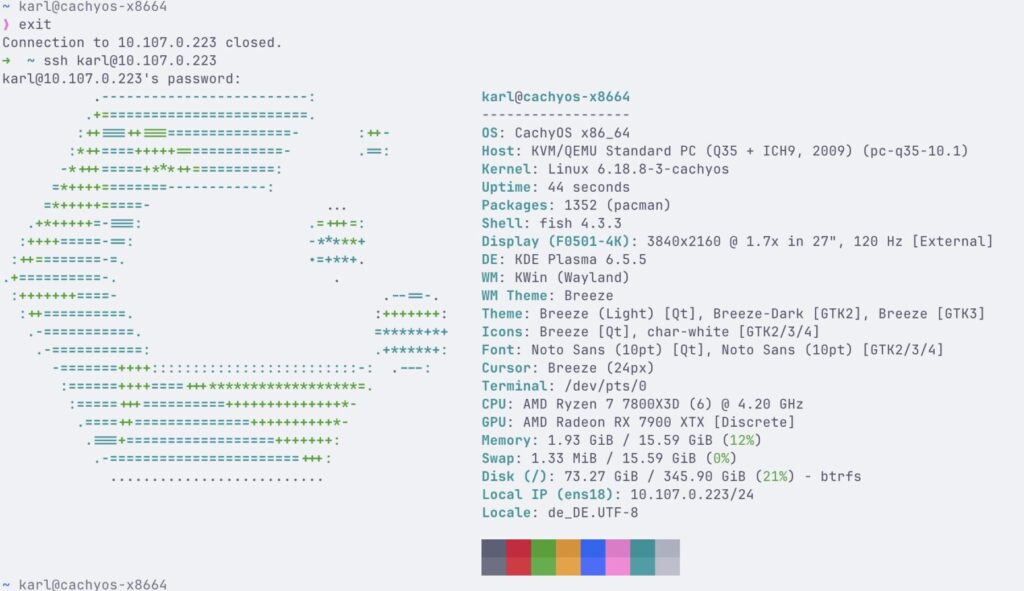
You should now be able to SSH into your VM:
Screenshot
Testing
If you are lucky then everything works out of the box now. I am not lucky.
I couldn’t get games to start through Steam thy kept crashing, the issue seemed to be old / non-existent Vulkan drivers for the GPU.
Maybe that is why I have had issues? Who knows, it works now.
The rest is really simple:
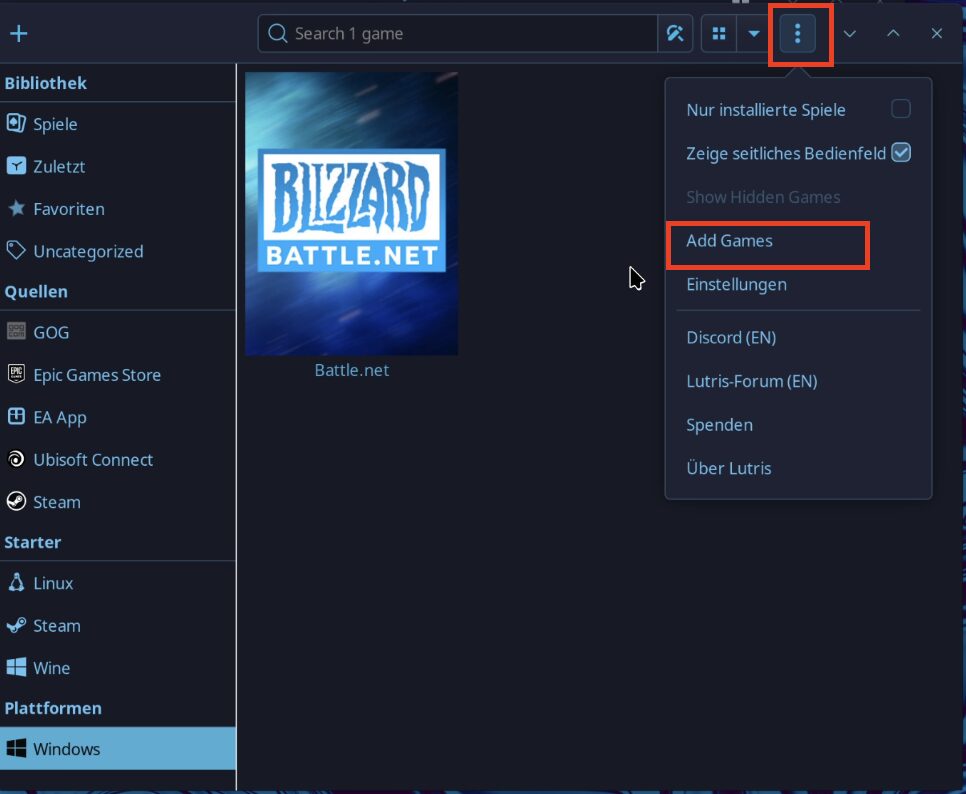
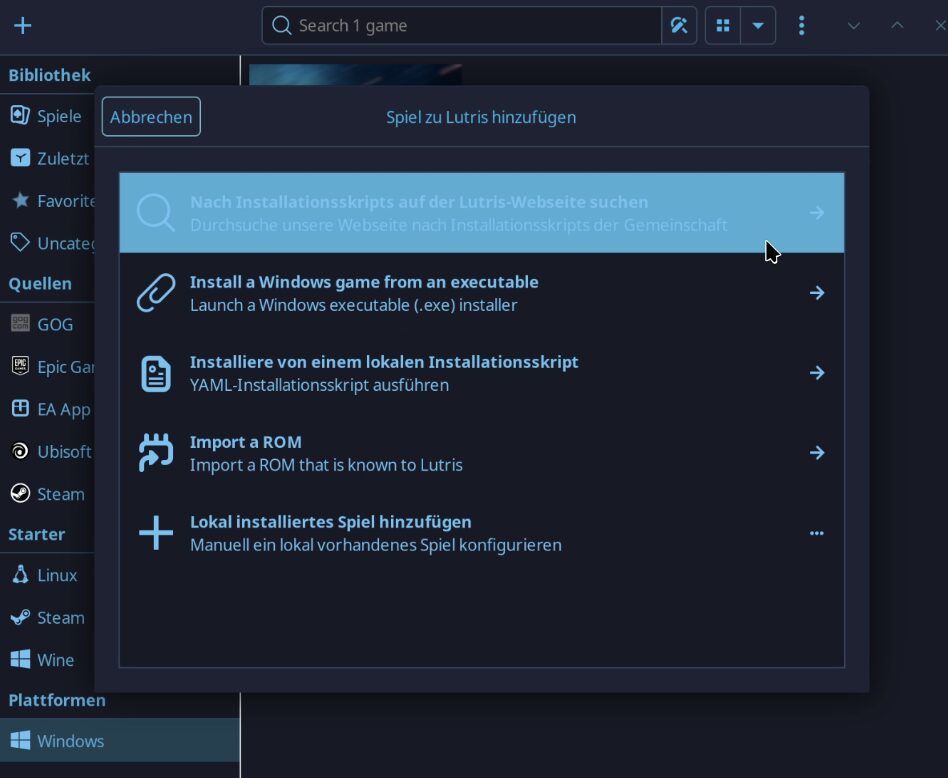
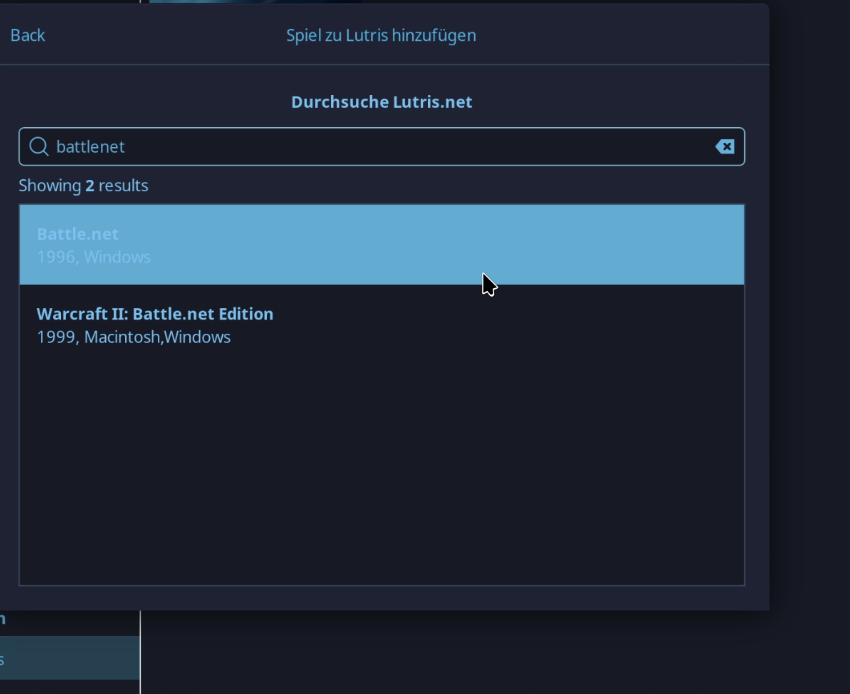
Start Lutris
Add new game
Search for “battlenet”
Install (follow the instructions, this is important)
ScreenshotScreenshot
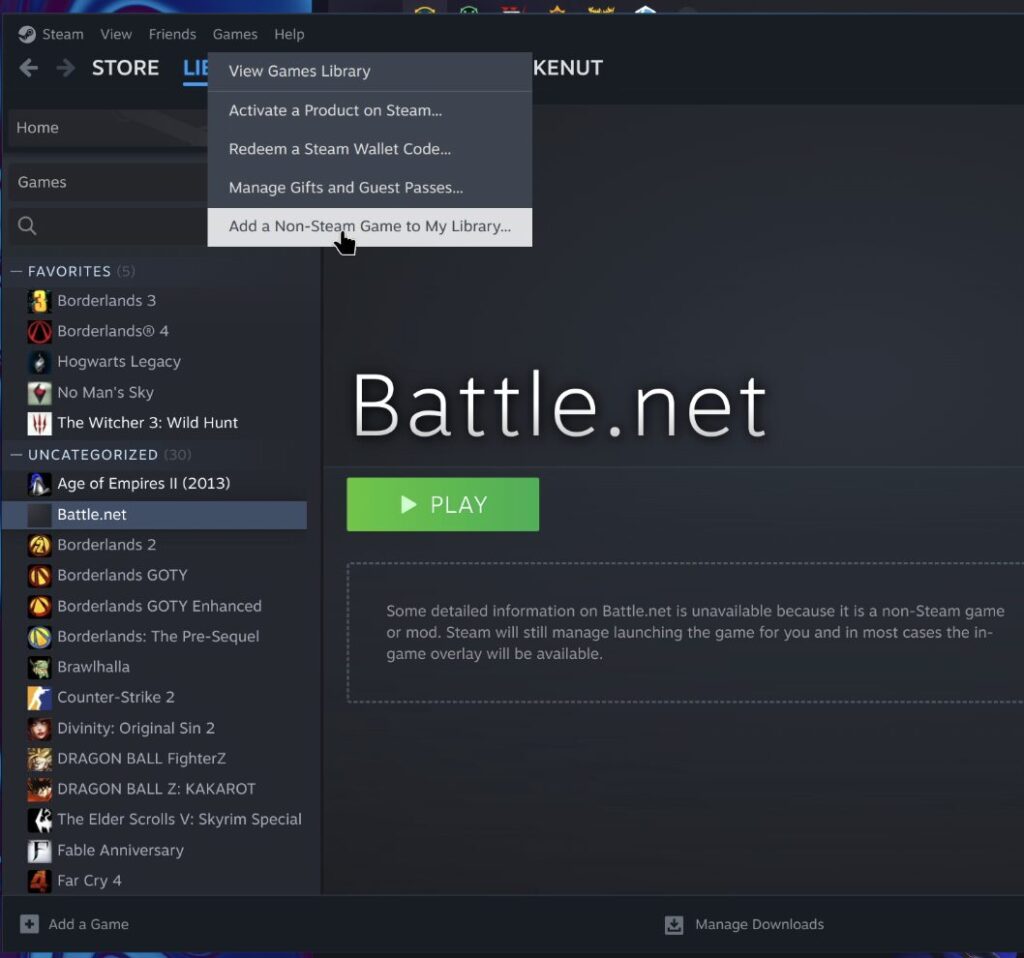
Once installed you need to add Battle.net App into Steam as a
Screenshot
Once you pressed play you can log in to your Battle.net Account and start:
Screenshot
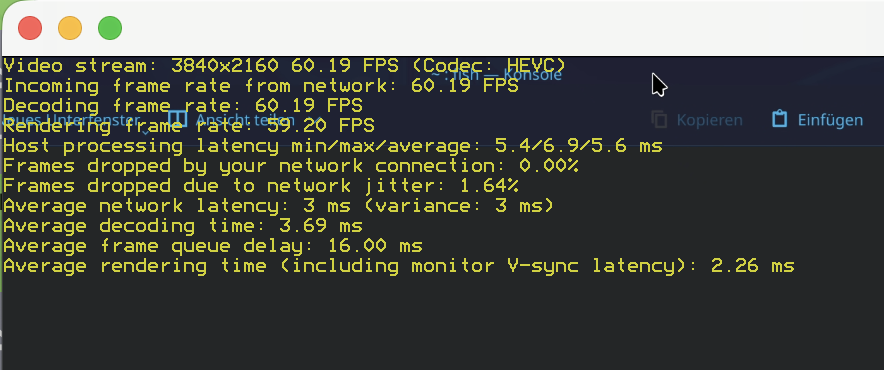
Resolution: 4K (3840×2160)
Framerate: Solid 60 FPS
Latency: ~5.6ms Host Processing (Insanely fast!)
Codec: HEVC (Hardware Encoding working perfectly)
Wrapping Up: The 48-Hour Debugging Marathon
I’m not going to lie to you, this wasn’t a quick “plug-and-play” tutorial. It took me a solid two days of tinkering, debugging, and staring at terminal logs to get this setup from “broken mess” to a high-performance cloud gaming beast.
We battled through Proxmox hooks, fought against dependency hell, and wrestled with Vulkan drivers until everything finally clicked.
I honestly hope this post acts as the shortcut I wish I had. If this guide saves you even just an hour of the headaches I went through, then every second of my troubleshooting was worth it.
And if you’re still stuck? Just know that we have suffered together, and you are not alone in the Linux trenches! 😂
For my next experiment, I think I’m going to give Bazzite a spin. I’ve heard great things about its “out-of-the-box” simplicity and stability. But let’s be real for a second: Bazzite isn’t Arch-based. If I switch, I lose the sacred ability to drop “I use Arch, btw” into casual conversation, and I’m not sure I’m emotionally ready to give up those bragging rights just yet.
Anyway, thank you so much for sticking with me to the end of this guide. You made it!
For a long time, I was a loyal subscriber to ChatGPT Plus. I happily paid the €23.99/month to access the best AI models. But recently, my focus shifted. I’m currently optimizing my finances to invest more in index ETFs and aim for early retirement (FIRE). Every Euro counts.
That’s when I stumbled upon a massive opportunity: Gemini Advanced.
I managed to snag a promotional deal for Gemini Advanced at just €8.99/month. That is nearly 65% cheaper than ChatGPT Plus for a comparable, and in some ways superior, feature set. Multimodal capabilities, huge context windows, and deep Google integration for the price of a sandwich? That is an immediate win for my portfolio.
(Not using AI obviously is not an option anymore in 2026, sorry not sorry)
The Developer Nightmare: Scraping ChatGPT
As a developer, I love automating tasks. With ChatGPT, I built my own “API” to bypass the expensive official token costs. I wrote a script to automate the web interface, but it was a maintenance nightmare.
The ChatGPT website and app seemed to change weekly. Every time they tweaked a div class or a button ID, my script broke. I spent more time fixing my “money-saving” tool than actually using it. It was painful, annoying, and unreliable.
The Python Upgrade: Unlocking Gemini
When I switched to Gemini, I looked for a similar solution and found an open-source gem: Gemini-API by HanaokaYuzu.
This developer has built an incredible, stable Python wrapper for the Gemini Web interface. It pairs perfectly with my new subscription, allowing me to interact with Gemini Advanced programmatically through Python.
I am now paying significantly less money for a cutting-edge AI model that integrates seamlessly into my Python workflows. If you are looking to cut subscriptions without cutting capabilities, it’s time to look at Gemini.
The Setup Guide
How to Set Up Your Python Wrapper
If you want to use the HanaokaYuzu wrapper to mimic the web interface, you will need to grab your session cookies. This effectively “logs in” the script as you.
⚠️ Important Note: This method relies on your browser cookies. If you log out of Google or if the cookies expire, you will need to repeat these steps. For a permanent solution, use the official Gemini API and Google Cloud.
Step 1: Get Your Credentials
You don’t need a complex API key for this wrapper; you just need to prove you are a human. Here is how to find your __Secure-1PSID and __Secure-1PSIDTS tokens: Copy the long string of characters from the Value column for both.
Open your browser (Chrome, Firefox, or Edge) and navigate to gemini.google.com.
Ensure you are logged into the Google account you want to use.
Open the Developer Tools:
Windows/Linux: Press F12 or Ctrl + Shift + I.
Mac: Press Cmd + Option + I.
Navigate to the Application tab (in Chrome/Edge) or the Storage tab (in Firefox).
Ensure you are logged into the Google account you want to use.
On the left sidebar, expand the Cookies dropdown and select https://gemini.google.com.
Look for the following two rows in the list:
__Secure-1PSID
__Secure-1PSIDTS
Step 2: Save the Cookies
Add a .env to your coding workspace:
# Gemini API cookiesSECURE_1PSID=g.a00SECURE_1PSIDTS=sidts-CjE
Examples
Automating Image Generation
We have our cookies, we have our wrapper, and now we are going to build with Nano Banana. This script will hit the Gemini API, request a specific image, and save it locally, all without opening a browser tab.
Here is the optimized, async-ready Python script:
import asyncioimport osimport sysfrom pathlib import Path# Third-party importsfrom dotenv import load_dotenvfrom gemini_webapi import GeminiClient, set_log_levelfrom gemini_webapi.constants import Model# Load environment variablesload_dotenv()Secure_1PSID = os.getenv("SECURE_1PSID")Secure_1PSIDTS = os.getenv("SECURE_1PSIDTS")# Enable logging for debuggingset_log_level("INFO")defget_client():"""Initialize the client with our cookies."""return GeminiClient(Secure_1PSID, Secure_1PSIDTS, proxy=None)asyncdefgen_and_edit():# Setup paths temp_dir = Path("temp") temp_dir.mkdir(exist_ok=True)# Import our local watermark remover (see next section)# We add '.' to sys.path to ensure Python finds the file sys.path.append('.')try:from watermark_remover import remove_watermarkexceptImportError:print("Warning: Watermark remover module not found. Skipping cleanup.") remove_watermark =None client = get_client()await client.init() prompt ="Generate a photorealistic picture of a ragdoll cat dressed as a baker inside of a bakery shop"print(f"🎨 Sending prompt: {prompt}") response =await client.generate_content(prompt)for i, image inenumerate(response.images): filename =f"cat_{i}.png" img_path = temp_dir / filename# Save the raw image from Geminiawait image.save(path="temp/", filename=filename, verbose=True)# If we have the remover script, clean the image immediatelyif remove_watermark:print(f"✨ Polishing image: {img_path}") cleaned = remove_watermark(img_path) cleaned.save(img_path)print(f"✅ Done! Saved to: {img_path}")if__name__=="__main__": asyncio.run(gen_and_edit())
If you have ever tried running a high-quality image generator (like Flux or SDXL) on your own laptop, you know the pain. You need massive amounts of VRAM, a beefy GPU, and patience. Using Gemini offloads that heavy lifting to Google’s supercomputers, saving your hardware.
But there is a “tax” for this free cloud compute: The Watermark.
Gemini stamps a semi-transparent logo on the bottom right of every image. While Google also uses SynthID (an invisible watermark for AI detection), the visible logo ruins the aesthetic for professional use.
The Fix: Mathematical Cleaning
You might think you need another AI to “paint over” the watermark, but that is overkill. Since the watermark is always the same logo applied with the same transparency, we can use Reverse Alpha Blending.
I found an excellent Python implementation by journey-ad (ported to Python here) that subtracts the known watermark values from the pixels to reveal the original colors underneath.
⚠️ Important Requirement: To run the script below, you must download the alpha map files (bg_48.png and bg_96.png) from the original repository and place them in the same folder as your script.
Here is the cleaning module:
#!/usr/bin/env python3"""Gemini Watermark Remover - Python ImplementationPorted from journey-ad/gemini-watermark-remover"""import sysfrom pathlib import PathfromPILimport Imageimport numpy as npfrom io import BytesIO# Ensure bg_48.png and bg_96.png are in this folder!ASSETS_DIR= Path(__file__).parentdefload_alpha_map(size):"""Load and calculate alpha map from the background assets.""" bg_path =ASSETS_DIR/f"bg_{size}.png"ifnot bg_path.exists():raiseFileNotFoundError(f"Missing asset: {bg_path} - Please download from repo.") bg_img = Image.open(bg_path).convert('RGB') bg_array = np.array(bg_img, dtype=np.float32)# Normalize to [0, 1]return np.max(bg_array, axis=2) /255.0# Cache the maps so we don't reload them every time_ALPHA_MAPS= {}defget_alpha_map(size):if size notin_ALPHA_MAPS:_ALPHA_MAPS[size] = load_alpha_map(size)return_ALPHA_MAPS[size]defdetect_watermark_config(width, height):""" Gemini uses a 96px logo for images > 1024px, and a 48px logo for everything else. """if width >1024and height >1024:return {"logo_size": 96, "margin": 64}else:return {"logo_size": 48, "margin": 32}defremove_watermark(image, verbose=False):""" The Magic: Reverses the blending formula: original = (watermarked - alpha * logo) / (1 - alpha) """# Load image and convert to RGBifisinstance(image, (str, Path)): img = Image.open(image).convert('RGB')elifisinstance(image, bytes): img = Image.open(BytesIO(image)).convert('RGB')else: img = image.convert('RGB') width, height = img.size config = detect_watermark_config(width, height) logo_size = config["logo_size"] margin = config["margin"]# Calculate position (Bottom Right) x = width - margin - logo_size y = height - margin - logo_sizeif x <0or y <0:return img # Image too small# Get the math ready alpha_map = get_alpha_map(logo_size) img_array = np.array(img, dtype=np.float32)LOGO_VALUE=255.0# The watermark is whiteMAX_ALPHA=0.99# Prevent division by zero# Process only the watermark areafor row inrange(logo_size):for col inrange(logo_size): alpha = alpha_map[row, col]# Skip noiseif alpha <0.002: continue alpha =min(alpha, MAX_ALPHA)# Apply the reverse blend to R, G, B channelsfor c inrange(3): pixel_val = img_array[y + row, x + col, c] restored = (pixel_val - alpha *LOGO_VALUE) / (1.0- alpha) img_array[y + row, x + col, c] =max(0, min(255, round(restored)))return Image.fromarray(img_array.astype(np.uint8), 'RGB')# Main block for CLI usageif__name__=="__main__":iflen(sys.argv) <2:print("Usage: python remover.py <image_path>") sys.exit(1) img_path = Path(sys.argv[1]) result = remove_watermark(img_path, verbose=True) output = img_path.parent /f"{img_path.stem}_clean{img_path.suffix}" result.save(output)print(f"Saved cleaned image to: {output}")
You could now build som etching with FastAPI on top of this and have your own image API! Yay.
The “LinkedIn Auto-Pilot” (With Memory)
⚠️ The Danger Zone (Read This First)
Before we look at the code, we need to address the elephant in the room. What we are doing here is technically against the Terms of Service.
When you use a wrapper to automate your personal Google account:
Session Conflicts: You cannot easily use the Gemini web interface and this Python script simultaneously. They fight for the session state.
Chat History: This script will flood your Gemini sidebar with hundreds of “New Chat” entries.
Risk: There is always a non-zero risk of Google flagging the account. Do not use your primary Google account for this.
Now that we are all adults here… let’s build something cool.
The Architecture: Why “Human-in-the-Loop” Matters
I’ve tried fully automating social media before. It always ends badly. AI hallucinates, it gets the tone wrong, or it sounds like a robot.
That is why I built a Staging Environment. My script doesn’t post to LinkedIn. It posts to Flatnotes (my self-hosted note-taking app).
The Workflow:
Python Script wakes up.
Loads Memory: Checks memory.json to see what we talked about last week (so we don’t repeat topics).
Generates Content: Uses a heavy-duty system prompt to create a viral post.
Staging: Pushes the draft to Flatnotes via API.
Human Review: I wake up, read the note, tweak one sentence, and hit “Post.”
The Code: The “Viral Generator”
This script uses asyncio to handle the network requests and maintains a local JSON database of past topics.
Key Features:
JSON Enforcement: It forces Gemini to output structured data, making it easy to parse.
Topic Avoidance: It reads previous entries to ensure fresh content.
Psychological Prompting: The prompt explicitly asks for “Fear & Gap” and “Thumb-Stoppers” marketing psychology baked into the code.
from random import randintimport timeimport aiohttpimport datetimeimport jsonimport osimport asynciofrom gemini_webapi import GeminiClient, set_log_levelfrom dotenv import load_dotenvload_dotenv()# Set log level for debuggingset_log_level("INFO")MEMORY_PATH= os.path.join(os.path.dirname(__file__), "memory.json")HISTORY_PATH= os.path.join(os.path.dirname(__file__), "history.json")FLATNOTES_API_URL="https://flatnotes.notarealdomain.de/api/notes/LinkedIn"FLATNOTES_USERNAME= os.getenv("FLATNOTES_USERNAME")FLATNOTES_PASSWORD= os.getenv("FLATNOTES_PASSWORD")Secure_1PSID = os.getenv("SECURE_1PSID")Secure_1PSIDTS = os.getenv("SECURE_1PSIDTS")asyncdefpost_to_flatnotes(new_post):""" Fetches the current note, prepends the new post, and updates the note using Flatnotes API with basic auth. """ifnotFLATNOTES_USERNAMEornotFLATNOTES_PASSWORD:print("[ERROR] FLATNOTES_USERNAME or FLATNOTES_PASSWORD is not set in .env. Skipping Flatnotes update." )return token_url ="https://notes.karlcloud.de/api/token"asyncwith aiohttp.ClientSession() as session:# 1. Get bearer token token_payload = {"username": FLATNOTES_USERNAME, "password": FLATNOTES_PASSWORD}asyncwith session.post(token_url, json=token_payload) as token_resp:if token_resp.status !=200:print(f"[ERROR] Failed to get token: {token_resp.status}")return token_data =await token_resp.json() access_token = token_data.get("access_token")ifnot access_token:print("[ERROR] No access_token in token response.")return headers = {"Authorization": f"Bearer {access_token}"}# 2. Get current note contentasyncwith session.get(FLATNOTES_API_URL, headers=headers) as resp:if resp.status ==200:try: data =await resp.json() current_content = data.get("content", "")except aiohttp.ContentTypeError:# Fallback: treat as plain text current_content =await resp.text()else: current_content =""# Prepend new post updated_content =f"{new_post}\n\n---\n\n"+ current_content patch_payload = {"newContent": updated_content}asyncwith session.patch(FLATNOTES_API_URL, json=patch_payload, headers=headers ) as resp:if resp.status notin (200, 204):print(f"[ERROR] Failed to update Flatnotes: {resp.status}")else:print("[INFO] Flatnotes updated successfully.")defsave_history(new_json): arr = []if os.path.exists(HISTORY_PATH):try:withopen(HISTORY_PATH, "r", encoding="utf-8") as f: arr = json.load(f)ifnotisinstance(arr, list): arr = []exceptException: arr = [] arr.append(new_json)withopen(HISTORY_PATH, "w", encoding="utf-8") as f: json.dump(arr, f, ensure_ascii=False, indent=2)return arrdefload_memory():ifnot os.path.exists(MEMORY_PATH):return []try:withopen(MEMORY_PATH, "r", encoding="utf-8") as f: data = json.load(f)ifisinstance(data, list):return datareturn []exceptException:return []defsave_memory(new_json): arr = load_memory() arr.append(new_json) arr = arr[-3:] # Keep only last 3withopen(MEMORY_PATH, "w", encoding="utf-8") as f: json.dump(arr, f, ensure_ascii=False, indent=2)return arrdefget_client():return GeminiClient(Secure_1PSID, Secure_1PSIDTS, proxy=None)defget_current_date():return datetime.datetime.now().strftime("%d. %B %Y")asyncdefexample_generate_content(): client = get_client()await client.init() chat = client.start_chat(model="gemini-3.0-pro") memory_entries = load_memory() memory_str =""if memory_entries: memory_str ="\n\n---\nVergangene LinkedIn-Posts (letzte 3):\n"+"\n".join( [ json.dumps(entry, ensure_ascii=False, indent=2)for entry in memory_entries ] ) prompt = (""" **Role:** Du bist ein weltklasse LinkedIn-Strategist (Top 1% Creator) und Verhaltenspsychologe. **Mission:** Erstelle einen viralen LinkedIn-Post, kurz knapp auf den punkt, denn leute lesen nur wenig und kurz, der mich als die unangefochtene Autorität für Cybersecurity & AI Governance in der DACH-Region etabliert. **Ziel:** Maximale Reichweite (100k Follower Strategie) + direkte Lead-Generierung für "https://karlcom.de" (High-Ticket Consulting). **Output Format:** Ausschließlich valides JSON. **Datum:** Heute ist der """+str(get_current_date())+""" nutze nur brand aktuelle Themen. **PHASE 1: Deep Intelligence (Google Search)** Nutze Google Search. Suche nach "Trending News Cybersecurity AI Cloud EU Sovereignty last 24h". Finde den "Elephant in the room" – das Thema, das C-Level Manager (CISO, CTO, CEO) gerade nachts wach hält, über das aber noch keiner Tacheles redet. * *Fokus:* Große Schwachstellen, Hackerangriffe, Datenleaks, AI, Cybersecurity, NIS2-Versäumnisse, Shadow-AI Datenlecks, Cloud-Exit-Szenarien. * *Anforderung:* Es muss ein Thema mit finanziellem oder strafrechtlichem Risiko sein. **PHASE 2: Die "Viral Architecture" (Konstruktion)** Schreibe den Post auf DEUTSCH. Befolge strikt diese 5-Stufen-Matrix für Viralität: **1. The "Thumb-Stopper" (Der Hook - Zeile 1-2):** * Keine Fragen ("Wussten Sie...?"). * Keine Nachrichten ("Heute wurde Gesetz X verabschiedet"). * **SONDERN:** Ein harter Kontrarian-Standpunkt oder eine unbequeme Wahrheit. * *Stil:* "Ihr aktueller Sicherheitsplan ist nicht nur falsch. Er ist fahrlässig." * *Ziel:* Der Leser spürt einen körperlichen Impuls, weiterzulesen. **2. The "Fear & Gap" (Die Agitation):** * Erkläre die Konsequenz der News aus Phase 1. * Nutze "Loss Aversion": Zeige auf, was sie verlieren (Geld, Reputation, Job), wenn sie das ignorieren. * Nutze kurze, rhythmische Sätze (Staccato-Stil). Das erhöht die Lesegeschwindigkeit massiv. **3. The "Authority Bridge" (Die Wende):** * Wechsle von Panik zu Kompetenz. * Zeige auf, dass blinder Aktionismus jetzt falsch ist. Man braucht Strategie. * Hier etablierst du deinen Status: Du bist der Fels in der Brandung. **4. The "Soft Pitch" (Die Lösung):** * Biete **Karlcom.de** als exklusive Lösung an. Nicht betteln ("Wir bieten an..."), sondern feststellen: * *Wording:* "Das ist der Standard, den wir bei Karlcom.de implementieren." oder "Deshalb rufen uns Vorstände an, wenn es brennt." **5. The "Engagement Trap" (Der Schluss):** * Stelle eine Frage, die man nicht mit "Ja/Nein" beantworten kann, sondern die eine Meinung provoziert. (Treibt den Algorithmus). * Beende mit einem imperativen CTA wie zum Beispiel: "Sichern wir Ihre Assets." **PHASE 3: Anti-AI & Status Checks** * **Verbotene Wörter (Sofortiges Disqualifikations-Kriterium):** "entfesseln", "tauchen wir ein", "nahtlos", "Gamechanger", "In der heutigen Welt", "Synergie", "Leuchtturm". * **Verbotene Formatierung:** Keine **fetten** Sätze (wirkt werblich). Keine Hashtag-Blöcke > 3 Tags. * **Emojis:** Maximal 2. Nur "Status-Emojis" (📉, 🛑, 🔒, ⚠️). KEINE Raketen 🚀. **PHASE 4: JSON Output** Erstelle das JSON. Der `post` String muss `\n` für Zeilenumbrüche nutzen. **Output Schema:** ```json { "analyse": "Kurze Erklärung, warum dieses Thema heute viral gehen wird (Psychologischer Hintergrund).", "thema": "Titel des Themas", "source": "Quelle", "post": "Zeile 1 (Thumb-Stopper)\n\nZeile 2 (Gap)\n\nAbsatz (Agitation)...\n\n(Authority Bridge)...\n\n(Pitch Karlcom.de)...\n\n(Engagement Trap)" } **Context für vergangene Posts, diese Themen solltest du erstmal vermeiden:**\n\n"""+ memory_str ) response =await chat.send_message(prompt.strip()) previous_session = chat.metadata max_attempts =3 newest_post_str =Nonedefformat_flatnotes_post(json_obj): heading =f"# {json_obj.get('thema', '').strip()}\n" analyse = json_obj.get('analyse', '').strip() analyse_block =f"\n```psychology\n{analyse}\n```\n"if analyse else"" post = json_obj.get('post', '').strip() source = json_obj.get('source', '').strip() source_block =f"\nQuelle: {source}"if source else""returnf"{heading}{analyse_block}\n{post}{source_block}"for attempt inrange(max_attempts):try: text = response.text.strip()if text.startswith("```json"): text = text[7:].lstrip()if text.endswith("```"): text = text[:-3].rstrip() json_obj = json.loads(text) save_memory(json_obj) save_history(json_obj) newest_post_str = format_flatnotes_post(json_obj)breakexceptException:print(response.text)print("- output was not valid json, retrying...")if attempt < max_attempts -1: previous_chat = client.start_chat(metadata=previous_session) response =await previous_chat.send_message(f"ENSURE PROPER JSON OUTPUT!\n\n{prompt}" )else:print("[ERROR] Failed to get valid JSON response after 3 attempts.")# Post to Flatnotes if we have a valid postif newest_post_str:await post_to_flatnotes(newest_post_str)asyncdefmain():await example_generate_content()if__name__=="__main__":for i inrange(50): asyncio.run(main()) time.sleep(randint(60, 300)) # Wait between 1 to 5 minutes before next run
The Result (Case Study)
Real-World Example: The “Ethics & Liability” Angle
To prove this isn’t just generating generic corporate fluff, let’s look at a raw output from a simulation run.
I set the internal date to January 31, 2026 (a future scenario regarding EU regulations) and asked the AI to find the “Elephant in the room” regarding Cybersecurity.
The AI didn’t choose a technical topic like “Firewalls.” It chose Personal Liability. It identified that C-Level executives are terrified of going to jail or losing personal assets due to negligence.
Here is the raw JSON output from the script. Pay attention to the analyse field, this is the AI “thinking” before it writes.
{"analyse": "Psychologischer Hebel: 'Personal Accountability' & 'Optimism Bias'. C-Level-Führungskräfte leben oft in der Illusion, Cyber-Risiken durch die Einstellung eines CISO vollständig an diesen delegiert zu haben (Moral Hazard). Der 'Elephant in the room' am 31.01.2026 ist das Ende der Schonfrist für die NIS2-Umsetzung...","thema": "Der CISO-Irrtum: Warum Delegation Sie jetzt ins Gefängnis bringt","source": "EU NIS2 Enforcement Reports Q1 2026 / Handelsblatt","post": "Ihr CISO ist nicht Ihre Versicherung.\nEr ist Ihr potenzieller Belastungszeuge.\n\nDer Irrglaube vieler Vorstände hat im Januar 2026 ein jähes Ende gefunden.\n\nDie erste Welle der NIS2-Prüfungen rollt durch die DACH-Region.\nUnd die Aufsichtsbehörden suchen nicht nach technischen Fehlern.\nSie suchen nach 'Organisationsverschulden'.\n\nDas Szenario:\nEin Ransomware-Angriff legt die Produktion lahm.\nDer CEO sagt: 'Ich habe doch einen Top-CISO eingestellt. Das war sein Job.'\n\nDer Richter sagt: 'Nein. Die Überwachungspflicht ist nicht delegierbar.'\n\nWenn Sie Cyber-Resilienz als reine IT-Aufgabe behandeln, handeln Sie grob fahrlässig.\nDer CISO liefert die Technik.\nAber *Sie* liefern die Governance.\n\nWenn Sie das Risikoprofil Ihrer eigenen Supply Chain nicht ohne PowerPoint erklären können, haften Sie.\nNicht die GmbH.\nSie persönlich.\nMit Ihrem Privatvermögen.\n\n[...]\n\nSichern wir Ihre Assets. ⚖️"}
Why This Post Works (The Anatomy)
This output demonstrates exactly why we use the “Human-in-the-Loop” architecture with Flatnotes. The AI followed the 5-step viral matrix perfectly:
The Hook:“Ihr CISO ist nicht Ihre Versicherung. Er ist Ihr potenzieller Belastungszeuge.”
It attacks a common belief immediately. It’s controversial and scary.
The Agitation: It creates a specific scenario (Courtroom, Judge vs. CEO). It uses the psychological trigger of Loss Aversion (“Mit Ihrem Privatvermögen” / “With your private assets”).
The Authority Bridge: It stops the panic by introducing a clear concept: “Executive-Shield Standard.”
The Tone: It avoids typical AI words like “Synergy” or “Landscape.” It is short, punchy, and uses a staccato rhythm.
Summary
By combining Gemini’s 2M Context Window (to read news) with Python Automation (to handle the logic) and Flatnotes (for human review), we have built a content engine that doesn’t just “write posts”—it thinks strategically.
It costs me pennies in electricity, saves me hours of brainstorming, and produces content that is arguably better than 90% of the generic posts on LinkedIn today.
The Verdict
From Consumer to Commander
We started this journey with a simple goal: Save €15 a month by cancelling ChatGPT Plus. But we ended up with something much more valuable.
By switching to Gemini Advanced and wrapping it in Python, we moved from being passive consumers of AI to active commanders.
We built a Nano Banana Image Generator that bypasses the browser and cleans up its own mess (watermarks).
We engineered a LinkedIn Strategist that remembers our past posts, researches the news, and writes with psychological depth, all while we sleep.
Is This Setup for You?
This workflow is not for everyone. It is “hacky.” It relies on browser cookies that expire. It dances on the edge of Terms of Service.
Stick to ChatGPT Plus if: …can’t think of a reason, it is sub-par in every way
Switch to Gemini & Python if: You are a builder. You want to save money and you want to build custom workflows that no off-the-shelf product can offer (for free 😉).
The Final Word on “Human-in-the-Loop”
The most important lesson from our LinkedIn experiment wasn’t the code, it was the workflow. The AI generates the draft, but the Human (you) makes the decision.
Whether you are removing watermarks from a cat picture or approving a post about Cyber-Liability, the magic happens when you use AI to do the heavy lifting, leaving you free to do the creative directing.
Ever ask your mom for a shiny new Google, only to hear:
We have Google at home, son!
and then she proudly shows you her self-hosted SearXNG instance?
Yeah… me neither.
But today, let me play that role for you and introduce you to my very own SearXNG setup.
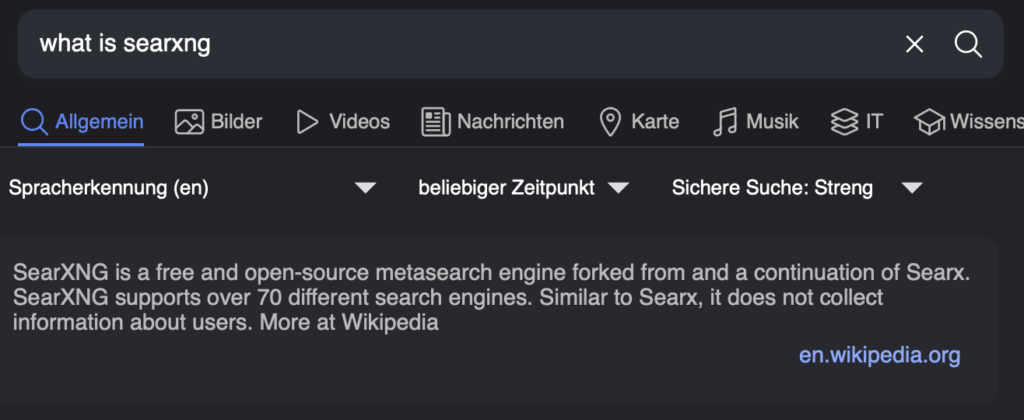
What is SearXNG ?
In other words (ChatGPTs):
SearxNG is a privacy-friendly meta-search engine. Instead of being one search engine like Google, it asks lots of engines at once (Google, Bing, Wikipedia, etc.) and shows you all the results together, without ads, tracking, or profiling.
Think of it like calling ten friends for advice instead of one, but none of them know who you are. 🤫 (kind of like you and I, fren ❤️)
Despite the intro, you don’t have to self-host SearXNG, a lot of people host an instance for you you can use, there is a directory here: https://searx.space
Screenshot
Self-Hosting SearXNG
Of course we’re hosting it ourselves, trusting someone else with your searches? Ha! Not today.
The Proxmox Community Scripts page is a gem, it makes spinning up your own VMs or containers as simple as a single bash command. The catch is that you are running random scripts from the internet on your system…ewww. Reviewing them is usually so annoying that if you’re truly paranoid, you might as well build it yourself.
Sure, you could go the Docker route, but then you’ve got to audit the Dockerfile too. Pick your poison. Personally, I stick with Proxmox Community Scripts, but I also keep a close eye with Wazuh, honeypots, and Grafana+Loki. Any network call I didn’t make or plan,I hear about it immediately.
Docker Option
If you prefer Docker, SearXNG has an official repo with a handy docker-compose file:
Honestly, I wish I had some epic war stories about running SearXNG… but it’s almost disappointingly easy 😂. I just left the standard settings as they are, no tweaks, no drama.
SearXNG API
Now here’s the fun part: the API.
In my opinion, the sexiest feature of SearXNG is its built-in search API. Normally, you’d have to pay through the nose for this kind of functionality to power your OSINT workflows, AI tools, or random scripts. With SearXNG, you get it for free. (Okay, technically the search engines themselves apply rate limits, but still, that’s a sweet deal.)
Enabling it is dead simple. Just flip the switch in your config:
nano/etc/searxng/settings.yml
Add:
search:safe_search: 2autocomplete: 'google'formats: - html - json# <- THIS!
Boom 💥 you’ve got yourself a free, self-hosted search API you can use like so:
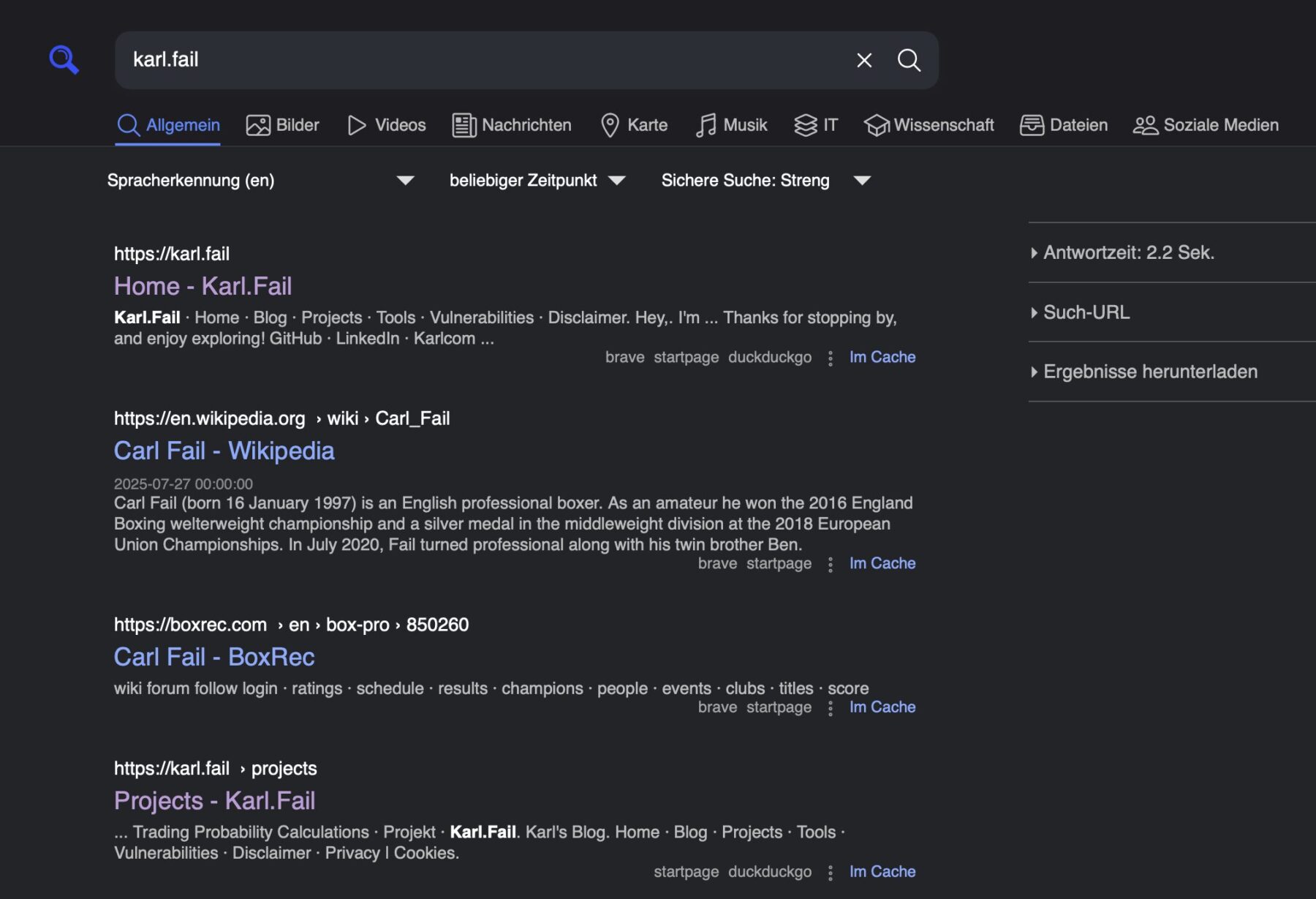
{"query": "karl.fail", "number_of_results": 0, "results": [{"url": "https://karl.fail/", "title": "Home - Karl.Fail", "content": "Karl.Fail \u00b7 Home \u00b7 Blog \u00b7 Projects \u00b7 Tools \u00b7 Vulnerabilities \u00b7 Disclaimer. Hey,. I'm ... Thanks for stopping by, and enjoy exploring! GitHub \u00b7 LinkedIn \u00b7 Karlcom\u00a0...", "publishedDate": null, "thumbnail": "", "engine": "brave", "template": "default.html", "parsed_url": ["https", "karl.fail", "/", "", "", ""], "img_src": "", "priority": "", "engines": ["brave", "startpage", "duckduckgo"], "positions": [1, 1, 1], "score": 9.0, "category": "general"}, {"url": "https://en.wikipedia.org/wiki/Carl_Fail", "title": "Carl Fail - Wikipedia", "content": "Carl Fail (born 16 January 1997) is an English professional boxer. As an amateur he won the 2016 England Boxing welterweight championship and a silver medal in the middleweight division at the 2018 European Union Championships. In July 2020, Fail turned professional along with his twin brother Ben.", "publishedDate": "2025-07-27T00:00:00", "thumbnail": "", "engine": "brave", "template": "default.html", "parsed_url": ["https", "en.wikipedia.org", "/wiki/Carl_Fail", "", "", ""], "img_src": "", "priority": "", "engines": ["brave", "startpage"],.......
When you query the API, you’ll get a nice clean JSON response back. (I trimmed this one down so you don’t have to scroll forever.)
Node-RED + SearXNG
And this is where things get fun(ner). Instead of just running curl commands, you can wire up SearXNG directly into Node-RED. That means you can chain searches into automations, OSINT pipelines, or even goofy side projects, without touching a line of code (except copy and pasting mine, you sly dog).
There are countless ways to use SearXNG, either as your daily driver for private search, or as a clean JSON API powering your tools, OSINT automations, and little gremlins you call “scripts.”
msg.payload = your search term. Everything else just wires the pieces together:
Flow:
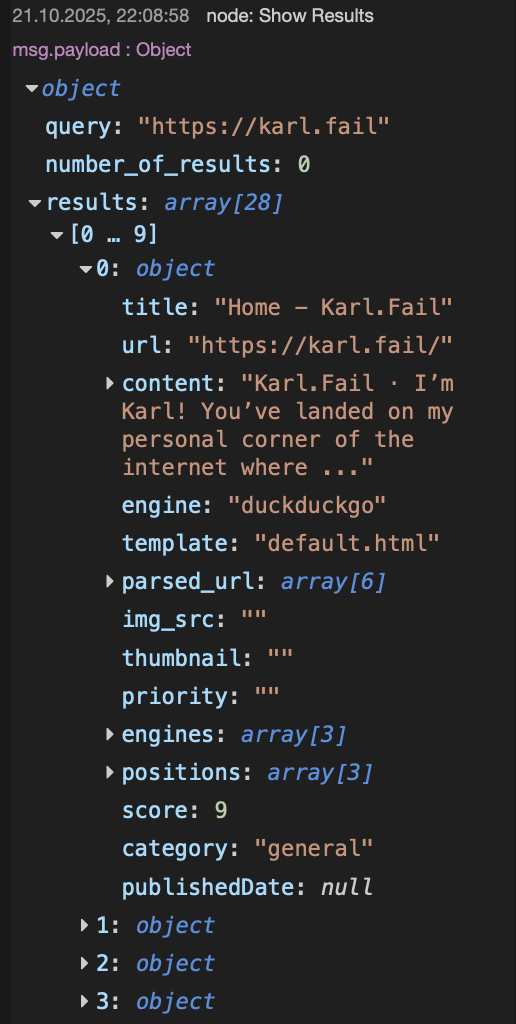
Inject → Function → HTTP Request → JSON → Debug
When you run the flow, you’ll see the results come back as clean JSON. In my case, it even found my own website and, as a bonus, it tells you which engine returned the hit (shout-out to “DuckDuckGo“).
Pretty cool. Pretty simple. And honestly, that’s the whole magic of SearXNG: powerful results without any unnecessary complexity
Summary
This was a quick tour of a seriously awesome tool. These days there are plenty of privacy-friendly search engines, you can trust them… or not 🤷♂️. The beauty of SearXNG is that you don’t have to: you can just host your own.
For the OSINT crowd (especially the developer types), this can be a real game-changer. Automate your dorks, feed the results into your local LLM, and suddenly you’ve got clean, filtered intelligence with almost no effort.
Whatever your use case, I highly recommend giving SearXNG a try. Show the project some love: star it, support it, spread the word, tell your mom about it and tell her I said hi 👋.
Today I’m showing you a few flows I use to quickly spin up Hetzner servers, run a task, and then tear them back down before they start charging rent.
I use Node-RED as my orchestrator, but honestly, you could do this in any language that can talk to an API. If you prefer Python, Go, or even Bash wizardry – go wild.
For the curious (or those who don’t trust random screenshots on the internet), the official Hetzner Cloud API docs are here: Hetzner Docs.
If you want to learn more about Node-RED go: Node-RED Docs
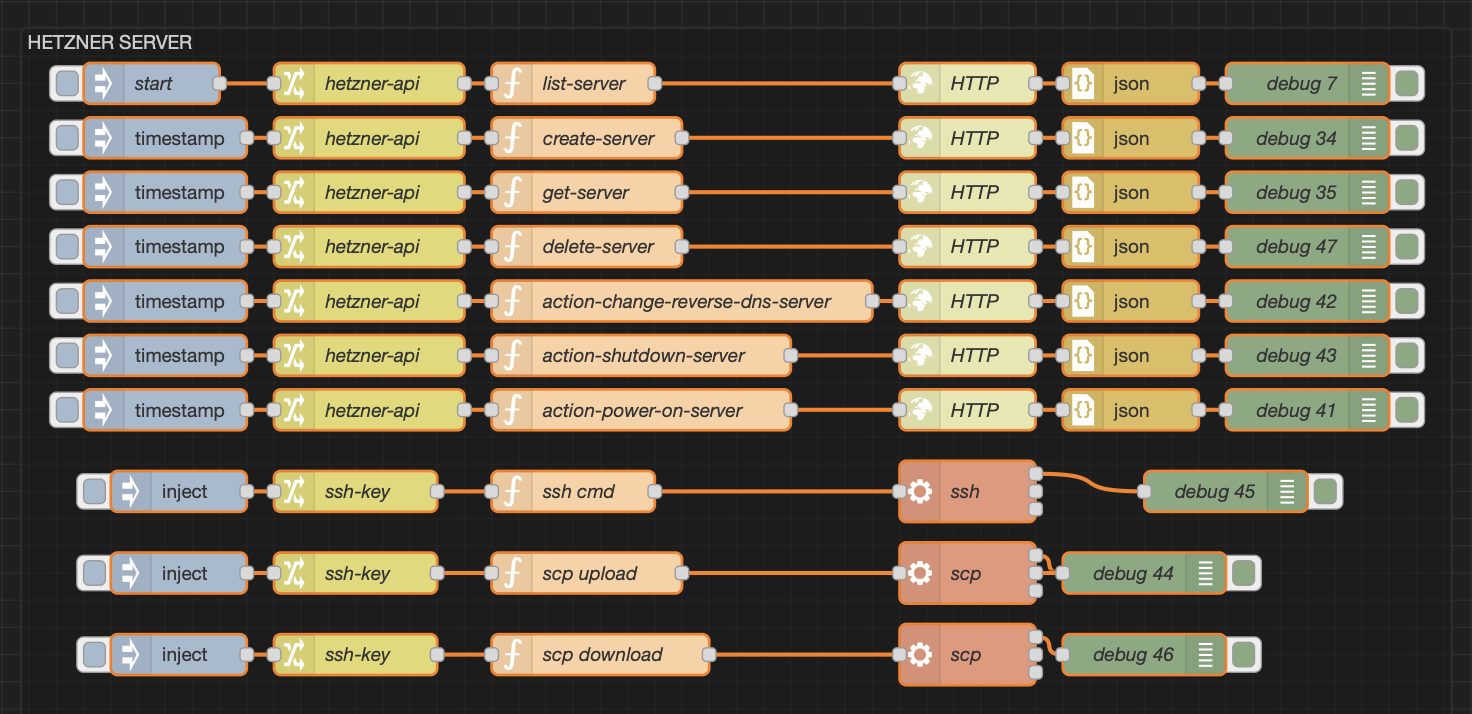
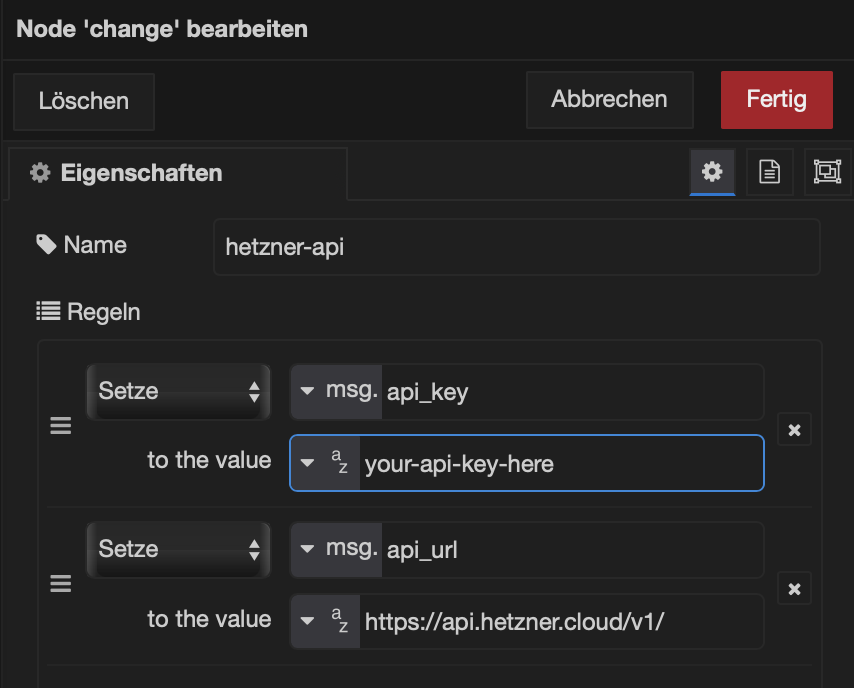
The Nodes
In my Change node, I usually stash constants like the API key and the API URL. That way I don’t have to scatter them across the flow like digital confetti. Keep it neat, keep it simple.
In the Function node is where the real magic happens. Unlike the Change node, the Function node carries a lot more logic. Don’t just skim it, read the comments. They’re basically the map through the jungle:
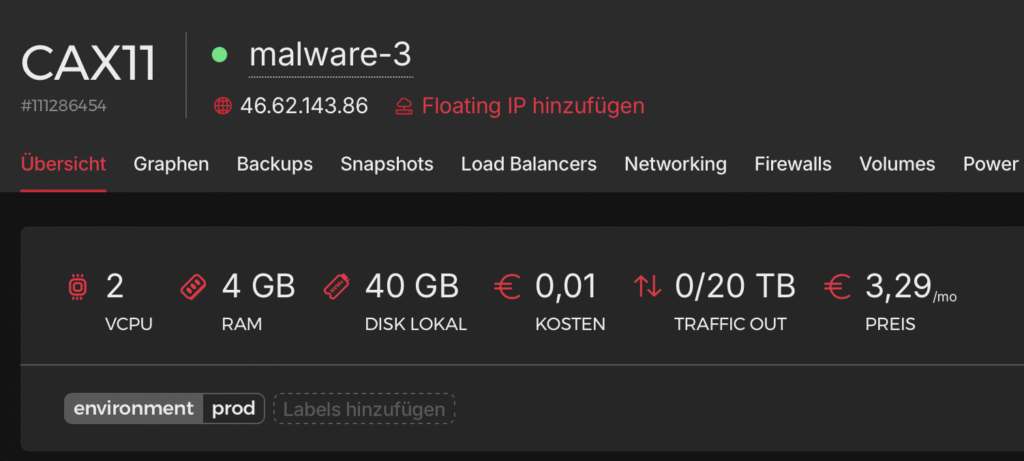
msg.user_name ="karl"// <- this is the user of your servermsg.server_name ="malware-3"// <- name of the serve ron Hetzner// Next is the pre-install script, this installs a bunch// of tools i need// I add some basic hardening like:// - no root login, no password login// - other SSH port constuserData=`#cloud-configusers: - name: ${msg.user_name} groups: users, admin sudo: ALL=(ALL) NOPASSWD:ALL shell: /bin/bash ssh_authorized_keys: - ssh-ed25519 SOMEKEYHERE [email protected]write_files: - path: /etc/ssh/sshd_config.d/ssh-hardening.conf content: | PermitRootLogin no PasswordAuthentication no Port 2222 KbdInteractiveAuthentication no ChallengeResponseAuthentication no MaxAuthTries 99 AllowTcpForwarding no X11Forwarding no AllowAgentForwarding no AuthorizedKeysFile .ssh/authorized_keys AllowUsers ${msg.user_name}package_update: truepackage_upgrade: truepackages: - fail2ban - ufw - apt-transport-https - ca-certificates - curl - zip - gnupg - lsb-release - software-properties-commonruncmd: - ufw allow 2222/tcp - ufw enable - curl -fsSL https://get.docker.com -o get-docker.sh - sh get-docker.sh - systemctl enable docker - systemctl start docker - apt upgrade -y - docker --version - docker compose version - reboot`;// this sets up the HTTP-Request node msg.method ="POST"msg.url = msg.api_url +"servers"msg.headers = {"Authorization": "Bearer "+ msg.api_key,"Content-Type": "application/json"};// actual API call bodymsg.payload = {"name": msg.server_name,"location": "hel1", // Helsinki Datacenter "server_type": "cax11", // smallest ARM server on Hetzner"start_after_create": true,"image": "debian-13", // OS"ssh_keys": ["karl-ssh-key" ],"user_data": userData,"labels": {"environment": "prod"// <- i like to put prod on my workers },"automount": false,"public_net": {"enable_ipv4": true,"enable_ipv6": false }};return msg;
⏱️ Setup time: About 10 minutes, coffee included. That’s enough to spin it up, install everything, and feel like you’ve actually been productive.
The API response you’ll get looks something like this:
I trimmed the response down a bit for clarity, but keep an eye on the id: 111286454. You’ll need that little guy for the next API calls.
Next up: let’s check the status of our server to make sure it’s actually alive and not just pretending. Keep the Change node and the HTTP Request node ( I am referring to the Request Node from the first screenshot of this post ) as they are. All you need is a shiny new Function node that looks like this:
If you head over to the Hetzner Cloud dashboard, you’ll see… well, absolutely nothing. (Insert a screenshot of emptiness here 😂).
Changing the reverse DNS
If you’re planning to host something on this server, you’ll probably want to set a reverse DNS (PTR record) so your domain name points back correctly. Mail servers especially are picky about this, without it, your emails might end up in spam faster than you can say “unsubscribe.“
As usual, keep the Change and HTTP Request nodes. Here’s the Function node you’ll need:
Before setting reverse DNS, double-check that your subdomain already has an A-Record pointing to the server’s IP. Technically, the Hetzner command doesn’t care, but trust me, you’ll want it in place.
Cloudflare: Set A-Record
Good news: we can automate that part, too. I’ll do a separate deep dive on it, but here’s the Function node you’ll need to set an A-Record through Cloudflare:
// zone_id = The Cloudflare Zone// bearer_token = Your Cloudflare API Token with DNS-Write permissionsmsg.url ="https://api.cloudflare.com/client/v4/zones/"+ msg.zone_id +"/dns_records";msg.headers = {"Authorization": "Bearer "+ msg.bearer_token};msg.payload = {"name": "subdomain.karl.fail","ttl": 3600,"type": "A","comment": "New worker from Node-RED","content": "46.62.143.86","proxied": true};return msg;
Nice, we’ve basically automated the whole worker lifecycle. ✅
Next step: run a long-running scan on the cloud host (I use nohup or tmux/screen), monitor it over SSH, and when it finishes scp the results back for processing. Example flow:
start the job on the cloud host with nohup <tool> & (or in a tmux session so you can attach later).
periodically SSH in and check the process (pgrep -a masscan / ps aux | grep masscan).
when it’s done, scp the output back to your machine and kick off post-processing.
Why do this in the cloud? Tools like masscan will absolutely saturate your home/office bandwidth. Running them remotely avoids choking your local network and gives you the throughput you actually need, plus you can tear the instance down when you’re done (no lingering bills, no guilt).
I keep my key paths in the SSH-key node and run a quick remote check to see if masscan is still alive.
What I send: build an SSH one-liner and parse the output.
StrictHostKeyChecking=no skips the “Are you sure you want to connect?“prompt when hitting a fresh server, and UserKnownHostsFile=/dev/null stops SSH from cluttering your known_hosts file with throwaway fingerprints.
Perfect for ephemeral workers—not so great for production, unless you enjoy living on the edge. 😅
Pro tip: write easy-to-parse commands
Instead of scraping messy output, keep things clean and structured. For example, here I check if my certspotter system service is running:
msg.cmd ="sudo systemctl is-active certspotter"
Run that via SSH on the remote system, then parse the response like so:
Now I’ve got a neat, machine-friendly healthcheck result I can reuse anywhere. No more grepping random strings or wondering if “running” really means running.
Bonus: Keep your workers warm
Sometimes you don’t want to constantly create and delete servers. Maybe you just want to pause a worker and spin it back up later without paying for full runtime.
That’s where two extra Function nodes come in handy: one for shutdown, one for power on.
👉 This way, you can park your worker, save on running costs, and still keep the storage around for when you need it again. (Storage will still cost a little, but it’s way cheaper than leaving the CPU humming all day.)
So, what did we cover? We learned how to use Node-RED to talk to the Hetzner Cloud API, spin up workers, run tasks, and clean them up again, without breaking a sweat (or the bank).
I also poked at the Firewall API endpoints in my dev environment, I didn’t include them here. They work just as smoothly, but honestly, I rarely bother with Hetzner firewalls since my workers are short-lived and get nuked when the job’s done. For anything long-running though, I’d definitely recommend offloading some of that work, otherwise a simple ufw setup does the trick for me.
If you’re anything like me, you’ve probably had one of those random late-night thoughts:
What if I built a scalable cluster of ClamAV instances, loaded it up with 35,000 YARA rules, and used it to really figure out what a file is capable of , whether it’s actually a virus or just acting suspicious?
It’s the kind of idea that starts as a “wouldn’t it be cool” moment and then slowly turns into “well… now I have to build it.“
And if that thought has never crossed your mind, that’s fine – because I’m going to walk you through it anyway.
How it Started
Like many of my projects, this one was born out of pure anger.
I was told, with a straight face, that scaling our ClamAV cluster into something actually usable would take multiple people, several days, extra resources, and probably outside help.
I told them I would do this in an afternoon, fully working, with REST API and Frontend
They laughed.
That same afternoon, I shipped the app.
How It’s Going
Step one: You upload a file.
The scanner gets to work and you wait for it to finish:
Once it’s done, you can dive straight into the results:
That first result was pretty boring.
So, I decided to spice things up by testing the Windows 11 Download Helper tool, straight from Microsoft’s own website.
You can see it’s clean , but it does have a few “invasive” features.
Most of these are perfectly normal for installer tools.
This isn’t a sandbox in the traditional sense. YARA rules simply scan the text inside files, looking for certain patterns or combinations, and then infer possible capabilities. A lot of the time, that’s enough to give you interesting insights, but it’s not a replacement for a full sandbox if you really want to see what the file can do in action.
The Setup
Here’s what you need to get this running:
HAProxy: for TLS-based load balancing
2 ClamAV instances: plus a third dedicated to updating definitions
Malcontent: YARA Scanner
Database: to store scan results
You’ll also need a frontend and an API… but we’ll get to that part soon.
defanalyze_capabilities(filepath: Path) -> dict[str, Any]: path = Path(filepath).resolve()ifnot path.exists() ornot path.is_file():raiseFileNotFoundError(f"File not found: {filepath}") cmd = ["docker","run","--rm","-v",f"{path.parent}:/scan","cgr.dev/chainguard/malcontent:latest","--format=json","analyze",f"/scan/{path.name}", ]try: result = subprocess.run(cmd, capture_output=True, text=True, check=True)return json.loads(result.stdout)except subprocess.CalledProcessError as e:raiseRuntimeError(f"malcontent failed: {e.stderr.strip()}") from eexcept json.JSONDecodeError as e:raiseValueError(f"Invalid JSON output from malcontent: {e}") from e
I’m not going to get into the whole frontend, it just talks to the API and makes things look nice.
For status updates, I use long polling instead of WebSockets. Other than that, it’s all pretty straightforward.
Final Thoughts
I wanted something that could handle large files too and so far, this setup delivers, since files are saved locally. For a production deployment, I’d recommend using something like Kata Containers, which is my go-to for running sketchy, untrusted workloads safely.
Always handle malicious files with caution. In this setup, you’re not executing anything, so you should mostly be safe, but remember, AV systems themselves can be exploited, so stay careful.
As for detection, I don’t think ClamAV alone is enough for solid malware protection. It’s better than nothing, but its signatures aren’t updated as frequently as I’d like. For a truly production-grade solution, I’d probably buy a personal AV product, build my own cluster and CLI tool for it, and plug that in. Most licenses let you use multiple devices, so you could easily scale to 10 workers for about €1.50 a month (just grab a license from your preferred software key site).
Of course, this probably violates license terms. I’m not a lawyer 😬
Anyway, I just wanted to show you something I built, so I built it, and now I’m showing it.
One day, this will be part of my Sandkiste tool suite. I’m also working on a post about another piece of Sandkiste I call “Data Loss Containment”, but that one’s long and technical, so it might take a while.
The journey to bringing you this guide was paved with rage and hardship. Before we go any further, let me be clear: local AI is nowhere near as good as ChatGPT or similar online tools. Without solid prompt engineering, you’ll mostly get weird, useless responses.
That said, DeepSeek-R1 (32B) is hands down the best local model I’ve ever used—but even then, it’s nowhere near the level of ChatGPT-4o in the cloud. To match that, you’d need the DeepSeek-R1 671B model, which is a mind-blowing 404GB. Running that locally? Yeah, that would be absolute madness.
Disclaimer: This post has some strong opinions about Linux distributions and hardware that some people may find disturbing or hurtful. Please don’t take it too serious.
Rant about AMD
Skip it, or read my raw unfiltered anger.
The image of this post perfectly reflects my mood.
A while ago, I decided to build an AI server at home to run models locally. My plan was to get an NVIDIA 4090, which at the time cost around 2000€. But then, my friend—who runs Arch as his daily driver (I should’ve seen the red flag)—was using an AMD RX 7900 XTX, which was only 900€ at the time. He hyped it up, saying, “Oh yeah, get this one! Same VRAM, super easy to set up, everything works flawlessly!”
I was intrigued.
As fate would have it, another friend echoed the same thing, insisting that for 24GB of VRAM, I wouldn’t find anything cheaper. And, well, that was actually true.
However, everything I read online told me that AMD GPUs lag far behind NVIDIA in every way, and worst of all, you’d always have to hack things together just to make them work. Still, on Black Friday, I caved and bought the AMD GPU.
I regret it every single day since putting it in. I hate it. It absolutely sucks.
So far, it has worked on Windows 11—but even there, it was a pain. And seriously, how do you even mess up Windows 11 support??
Then I switched to Ubuntu as my main OS (☹️). After two days of struggle (and reinstalling the entire OS three times), I somehow got it to work. I still don’t know what I did. Every guide on the internet gives different commands, different settings, and different advice. Most are for older AMD GPUs, almost none work for the newer models, and—just for fun—most of the essential tools don’t support the “new” AMD cards either.
I hate it. I hate it so much.
My mood
I will never buy an AMD GPU ever again. Even if they came with 100GB of VRAM and cost just 5€, I do not care.
Looking back, I would rather pay 2000€ for a GPU that just works than spend endless hours hacking together the most basic functionality. The sheer frustration of dealing with this mess infuriates me beyond words.
This post serves as both a rant and a personal reminder: Never. Ever. Ever. Buy. AMD. Hardware. Again.
To be honest, I’m just as disappointed in AMD CPUs. Their hardware transcoding is absolute trash.
From now on, it’s Intel and NVIDIA, forever and always.
Prerequisite
32GB RAM (with ComfyUI, bump that up to 40GB)
250GB SSD Storage
Debian 12 LXC
If you are more curious about my exact setup you’ll find a detailed list where you can check if yours is similar here: My Home Server: “PrettyLittleKitten” – A Personal Tech Haven. At the very least, your GPU should match (AMD RX 7900 XTX) to follow the tutorial step by step. If it doesn’t, chances are it’ll fail.
You need to install the kernel drivers on the host for passthrough to an LXC:
It’s important to note that the LXC must be privileged. I know there are guides for setting up an unprivileged one, but literally none of them worked—which only fueled my rage to unbearable levels.
You are free to install docker without using the convenience script.
GPU Passthrough
This heavily depends on your hardware and software.
If, like me, you have an AMD RX 7900 XTX and Proxmox 8.3.3, then you can just follow along. Otherwise—based on my own painful experience—you’ll likely need to find another guide.
Inside the LXC, run:
cat/etc/group|grep-w'render\|\video'
This will display the GIDs you need for passthrough in a second—so make sure to note them down:
In my case, “renderD128” is the part I need. To find yours, match the ID from the first command (e.g., 03:00.0) with the ID from the second command (e.g., 0000:03:00.0). Once they match, you’ll know which renderD* device corresponds to your GPU (the other one is the iGPU of the CPU, don’t use that).
In the Proxmox GUI, go to your LXC container’s “Resources” tab and click “Add” → “Device Passthrough“. Now, add the “video” and “render” devices using the GIDs you noted earlier:
Render device: Use the path for your graphics card and the GID from the LXC output.
Video device: Use /dev/kfd and the GID for “video” from the LXC output.
This is what your settings should look like (you may need to restart the LXC first).
After a restart of the container check to see if permission are correct:
Make sure that “root render” is the GPU and “root video” the Kernel Fusion Driver (kfd).
Kernel Fusion Driver
If you want to run ROCm-based GPU compute workloads, such as machine learning, OpenCL, or scientific computing, on your AMD GPU within Proxmox. It acts as the interface between the AMD GPU driver and user-space applications, enabling GPU acceleration for parallel computing tasks.
– ChatGPT-4o
Install AMD Software
We need to install some tools inside of our Debian LXC:
You can also refer to the official guide: Quick Start Installation Guide – ROCm (at the very least, check if the links are still valid by the time you’re reading this).
The download might take a while. Since I have a new AMD RX 7900 XTX, I need to use:
Since curl is not installed by default in the Debian LXC we’re using, we’ll need to install it first (if you filled this guide, you have it already). Then, we’ll run the install script from the Ollama website. Be patient—the download takes a while since it pulls about 30GB of data.
By the way, I love the Ollama website. The simple black-and-white design with rounded borders? 🤌 I’m a sucker for minimalistic aesthetics. (I hope you like my blog’s design too! 🕺)
Next Step: Testing with a Smaller Model
Before downloading the DeepSeek 32B model, we’ll first test with a smaller DeepSeek version. If your GPU matches mine, the larger model should work fine.
Now, run this command—it’s going to download a 1.5GB file, so the wait time depends on your internet speed:
ollamapulldeepseek-r1:1.5b
You can then test:
curl-XPOSThttp://localhost:11434/api/generate-d'{ "model": "deepseek-r1:1.5b", "prompt": "Tell me a funny story about my best friend Karl. 300 characters maximum.", "stream": false}'|jq.
Once upon a time, in the quiet town of Pawsley, there was Karl, a beloved kind cat who adored his three feline friends: Sam, Max, and Lily. Karl always had a warm smile and a habit of aiding others, often finding humor in unexpected places.
One crisp autumn afternoon, Karl spotted a bag of marbles on the park’s bench. Curious, he decided to play with them. To everyone’s surprise, a man walked by, holding a jar full of coins instead of marbles. “Hey, it’s you!” Karl exclaimed. The man, initially unimpressed, asked for his change. Karl suggested taking one marble in exchange and gave him the coins.
“Thank you,” the man thanked. Karl offered him a glass of water, knowing the jar was empty. “That’ll keep me happy,” he said. But as the water filled the glass, a strange ripple appeared on the floor. The man ran over to check but found nothing—no coins, just a tiny, pink spot.
“Wait, is it my pet?!” Karl pointed. The man laughed, looking suspiciously at Karl. “You saw that marble in there.” He handed Karl a piece of paper and said,”I need your help.”
Karl rolled on his back and rolled into the street. From behind him, he saw Sam, Max, and Lily with their usual spotlights on. Karl placed a paw on Sam’s paw, suggesting they might be related.
“Hey!” Max excitedly exclaimed. “My little sister is getting sick! Can you help me find her?”
Karl hesitated but followed Max to the neighbor’s yard. His friend found Lily, who was hiding somewhere. Karl helped Lily bring her back home, while Sam and Max watched in laughter. Karl’s kind words were met with cheers.
In the end, Karl became a beloved companion among Pawsley’s residents, not just for his love of marbles but also for his warmth and kindness.
Never interrupt an AI artist in the middle of their masterpiece. 🎨🤖 But yeah, the 300-Character-Limit was ignored.
Cleanup
Let’s get rid of the old files. But first, double-check before running these commands—they’ll wipe out all .sh and .deb files in /tmp.
ls-lh/tmp/*.sh/tmp/*.deb
The command above shows you what the command below will delete. Proceed if the displayed files are trash. The deleted files are irreversibly gone after this command:
rm-f/tmp/*.sh/tmp/*.debaptautoremove
Testing OpenWebUI with DeepSeek-R1 32B
The prompt I gave DeepSeek was “Give me a 10 word super short story about a cat named Paul.” – which is the name of my actual cat.
Well, not quite 10 words, but close enough. This was a cold start, meaning the model wasn’t loaded into VRAM yet—so yeah, it took a bit longer.
DeepSeek really put in some serious effort here, like it was deep in thought, sweating over every word. 😂 Considering all that, the result is absolutely hilarious:
Okay, so I need to come up with a 10-word super short story about a cat named Paul. Hmm, let’s see… The user gave an example: “Paul the cat climbed the fence, chasing a bird, then napped in the sun.” That’s pretty straightforward but conveys a little action and a bit of character.
I should think about what elements make a good 10-word story. It needs to have a clear subject (Paul), some action or activity, maybe an obstacle or goal, and perhaps a resolution or consequence. Since it’s so short, each word counts, so I need to be concise but still vivid.
Let me brainstorm some ideas about Paul the cat. Maybe he’s curious, playful, adventurous, or lazy. The example has him chasing a bird and then napping. Perhaps another activity? Maybe exploring somewhere, finding something, or having an interaction with another animal or person.
I should think of a simple structure: subject (Paul), action verb, some context, maybe an obstacle or additional detail, and a resolution. For example, “Paul pounced on the mouse but it escaped.” That’s 8 words. Maybe add more details to make it 10.
Or perhaps something like “Paul sat by the window watching birds chirp.” That’s also 8 words. Maybe include movement: “Paul raced through the garden chasing a butterfly.”
Wait, the user provided an example that starts with Paul doing an action (climbed), then another action (chasing), and ends with resting (napped). So perhaps following a similar structure would work well.
Let me try: “Paul explored the attic, found a toy, and took a nap.” That’s 9 words. Maybe add more detail or action. Or “Paul climbed the tree, met another cat, then curled up to sleep.”
Wait, that’s 10 words. Hmm, but it feels a bit flat. Maybe make the interaction more engaging: “Paul chased a squirrel around the yard and finally rested.” That’s 9 words. Could add something like “in the shade” at the end for 10.
Alternatively, maybe include some emotion or consequence: “Paul pounced on the ball, rolled over, and fell asleep.”
Wait, let me check word count. Each idea needs to be exactly 10 words. Let’s see:
Paul the cat climbed the fence, chasing a bird, then napped in the sun. (10 words)
So that’s the example given. I can try something similar but different.
Maybe focus on a different activity: “Paul discovered a sunny spot, curled up, and purred softly.” That’s 9 words. Maybe add more action or detail to make it 10.
Alternatively: “Paul leaped onto the counter, knocked over a bowl, then ate the leftovers.” That’s 10 words but maybe a bit long in description.
Another angle: “Paul wandered through the park, met a dog, and they played together.” That’s 9 words. Add something like “all day” at the end for 10.
Wait, perhaps include some obstacle or challenge: “Paul tried to catch a fish in the pond but got wet.” That’s 10 words. It includes an attempt, action, consequence.
Or maybe something more peaceful: “Paul stretched lazily on the rug, yawned, and drifted off.” 9 words. Add “to sleep” for 10.
I think I need to ensure each word adds value without being redundant. Let me try another approach:
Paul chased a butterfly in the garden until it flew away. (That’s 8 words. Maybe add “then rested” at the end: 10 words.)
Wait, but that might be too similar to the example.
Alternatively, focus on something unique about Paul: “Paul, the curious cat, explored every nook and cranny.” That’s 9 words. Maybe add “all day long” for 12; that’s too many.
Perhaps include an interaction with another animal or a person: “Paul meowed at the door, demanding attention, then curled up.” 9 words. Add “by the fire” for 10.
Wait, perhaps combine actions and consequences more effectively. Let me think of a scenario where Paul does something that leads to a natural conclusion in just 10 words.
How about: “Paul sneaked into the kitchen, stole a treat, then hid under the bed.” That’s 9 words. Maybe add “to digest” for 10.
Or maybe something more adventurous: “Paul climbed a tall tree, got stuck, and miaowed for help.” That’s 9 words. Add “from his owner” for 11; that’s too many.
Alternatively: “Paul caught a moth in the dark, played with it, then slept soundly.” 9 words. Maybe add “through the night” for 10.
I think I’m overcomplicating it. Let me go back to the example and see if I can structure something similar but different. The example has two actions (climbed, chasing) followed by a rest. So maybe another set of actions leading to a consequence or resolution.
Perhaps: “Paul chased his tail in circles until he panted.” That’s 8 words. Maybe add “then stopped to rest” for 10.
Alternatively: “Paul jumped on the sofa, knocked over a lamp, then slept.” But that’s 9 words; maybe add “peacefully” at the end for 10.
Wait, perhaps focus on Paul’s interaction with an object or another animal. Let me think of something unique but still within the 10-word limit.
Another idea: “Paul found a cozy spot under the stairs and napped.” That’s 8 words. Maybe add “after exploring all day” for 10.
Wait, that would be “Paul found a cozy spot under the stairs after exploring all day.” That’s 9 words. Hmm.
Alternatively: “Paul purred contentedly while basking in sunlight.” 7 words. Add some activity before that to make it 10.
I think I need to stick to a structure where Paul does something, then another action or consequence, and maybe ends with a state or rest.
Let me try again: “Paul climbed the fence, chased a butterfly, then napped in shade.” That’s 9 words. Maybe change “then” to “and” for flow: “climbed, chased, and napped” but that might not add up correctly.
Wait, let’s count the example given: “Paul the cat climbed the fence, chasing a bird, then napped in the sun.” That’s 10 words. So it includes his name, his action (climbed), context (the fence), another action (chasing), and the consequence (napped in the sun). I need to mirror that structure but with different actions.
So maybe: “Paul the cat explored the garden, found a mouse, then relaxed by the pond.” That’s 10 words. It follows a similar flow—action, context, additional action, consequence.
Alternatively: “Paul the cat pounced on a toy, rolled around, and fell asleep.” 9 words. Add “on the rug” for 10.
Wait, maybe make it more dynamic: “Paul the cat raced through the park, met a friend, then rested under a tree.” That’s 10 words. It shows activity, interaction, and rest.
I think that’s a good structure—action, context, another action or interaction, consequence. So putting it all together, I can create a concise story within the word limit.
– DeepSeek-R1:32B thoughts
Here you can see the electricity usage—a solid 450W for two minutes until things calmed down. Usually the server “idles” at around 50-53W, since I have a local SIEM and this website (along with a lot of other stuff) runs on it, it is never really really idle.
Both hardware and software went all in, pushing their limits… all for my short, 10-word cat story:
This does not prove that DeepSeek-R1 is a waste of electricity and ends up with a subpar result, rather that you probably do not need an advanced thinking model for such a super simple task.
Check out dolphin-mistral, also on a cold start only taking 4 seconds. The second message did not even take a second:
Bonus: ComfyUI
The Official Installation Guide: How to Install ComfyUI on Linux Alright, OpenWebUI now supports ComfyUI for image generation (still in beta at the time of writing). Here is the super quick start for ComfyUI, run these commands in your LXC:
Setting this up, especially with newer AMD GPUs, used to be a bit of a headache. I’m honestly glad I waited a bit—getting this to work wasn’t exactly painless, and I had to do a lot of digging through forums. But hey, it’s running now!
Next up, get some models from the Ollama page. If you have an AMD RX 7900 XTX, you should be able to run the 32B version of DeepSeek-R1 effortlessly. Technically, you can load models larger than your VRAM, but be warned—it’ll slow things down.
Also, don’t forget to secure your AI server and add valid SSL certificates, check out my post about it:
I set up firewall rules centrally on my Dream Machine, so my AI server can only communicate with the reverse proxy.
If your setup is different, you might want to handle this locally using UFW.
These Goodbye Message are Brought to you by AI
Aww, yaaaay! I totally loooove all your amazing readers <3 Wishing you guys the biiiggest luck with everything you dooove, okay? Dayyyyyybeeee~ 💕✨
– qwen2.5:32b
Love y’all, keep slaying in everything you do <3 Can’t wait to see what awesome things you have coming up. Bye for now! 👋🏼😉
– dolphin-mistral
Goodbye image I made with Flux Schnell and ComfyUI
EDIT 1 (04.02.2024)
I have downloaded and tested almost all popular models now and the only actually usable one for daily business like rewriting German emails or asking for expertise in German is qwen2.5 so far.
The uncensored Dolphin models are a lot of fun, but also kind of stink with German, which is of course because their underlying models aren’t good at German either.
The name Squidward comes from TAD → Threat Modelling, Attack Surface and Data. “Tadl” is the German nickname for Squidward from SpongeBob, so I figured—since it’s kind of a data kraken—why not use that name?
It’s a continuous observation and monitoring script that notifies you about changes in your internet-facing infrastructure. Think Shodan Monitor, but self-hosted.
Technology Stack
certspotter: Keeps an eye on targets for new certificates and sneaky subdomains.
Discord: The command center—control the bot, add targets, and get real-time alerts.
At this point, I gotta give a massive shoutout to ProjectDiscovery for open-sourcing some of the best recon tools out there—completely free! Seriously, a huge chunk of my projects rely on these tools. Go check them out, contribute, and support them. They deserve it!
(Not getting paid to say this—just genuinely impressed.)
How it works
I had to rewrite certspotter a little bit in order to accomodate a different input and output scheme, the rest is fairly simple.
Setting Up Directories
The script ensures required directories exist before running:
$HOME/squidward/data for storing results.
Subdirectories for logs: onlynew, allfound, alldedupe, backlog.
Running Subdomain Enumeration
squidward (certspotter) fetches SSL certificates to discover new subdomains.
subfinder further identifies subdomains from multiple sources.
Results are stored in logs and sent as notifications (to a Discord webhook).
DNS Resolution
dnsx takes the discovered subdomains and resolves:
A/AAAA (IPv4/IPv6 records)
CNAME (Canonical names)
NS (Name servers)
TXT, PTR, MX, SOA records
HTTP Probing
httpx analyzes the discovered subdomains by sending HTTP requests, extracting:
Status codes, content lengths, content types.
Hash values (SHA256).
Headers like server, title, location, etc.
Probing for WebSocket, CDN, and methods.
Vulnerability Scanning
nuclei scans for known vulnerabilities on discovered targets.
The scan focuses on high, critical, and unknown severity issues.
Port Scanning
rustscan finds open ports for each discovered subdomain.
If open ports exist, additional HTTP probing and vulnerability scanning are performed.
Automation and Notifications
Discord notifications are sent after each stage.
The script prevents multiple simultaneous runs by checking if another instance is active (ps -ef | grep “squiddy.sh”).
Randomization (shuf) is used to shuffle the scan order.
Main Execution
If another squiddy.sh instance is running, the script waits instead of starting.
If no duplicate instance exists:
Squidward (certspotter) runs first.
The main scanning pipeline (what_i_want_what_i_really_really_want()) executes in a structured sequence:
The Code
I wrote this about six years ago and just laid eyes on it again for the first time. I have absolutely no clue what past me was thinking 😂, but hey—here you go:
#!/bin/bash############################################### Single script usage:# echo "test.karl.fail" | ./httpx -sc -cl -ct -location -hash sha256 -rt -lc -wc -title -server -td -method -websocket -ip -cname -cdn -probe -x GET -silent# echo "test.karl.fail" | ./dnsx -a -aaaa -cname -ns -txt -ptr -mx -soa -resp -silent# echo "test.karl.fail" | ./subfinder -silent# echo "test.karl.fail" | ./nuclei -ni################################################## -----> globals <-----workdir="squidward"script_path=$HOME/$workdirdata_path=$HOME/$workdir/dataonly_new=$data_path/onlynewall_found=$data_path/allfoundall_dedupe=$data_path/alldedupebacklog=$data_path/backlog# -----------------------# -----> dir-setup <-----setup() {if [ !-d $backlog ]; thenmkdir $backlogfiif [ !-d $only_new ]; thenmkdir $only_newfiif [ !-d $all_found ]; thenmkdir $all_foundfiif [ !-d $all_dedupe ]; thenmkdir $all_dedupefiif [ !-d $script_path ]; thenmkdir $script_pathfiif [ !-d $data_path ]; thenmkdir $data_pathfi}# -----------------------# -----> subfinder <-----write_subfinder_log() {tee-a $all_found/subfinder.txt| $script_path/anew $all_dedupe/subfinder.txt|tee $only_new/subfinder.txt}run_subfinder() { $script_path/subfinder -dL $only_new/certspotter.txt-silent|write_subfinder_log; $script_path/notify -data $only_new/subfinder.txt-bulk-providerdiscord-idcrawl-silentsleep5}# -----------------------# -----> dnsx <-----write_dnsx_log() {tee-a $all_found/dnsx.txt| $script_path/anew $all_dedupe/dnsx.txt|tee $only_new/dnsx.txt}run_dnsx() { $script_path/dnsx -l $only_new/subfinder.txt-a-aaaa-cname-ns-txt-ptr-mx-soa-resp-silent|write_dnsx_log; $script_path/notify -data $only_new/dnsx.txt-bulk-providerdiscord-idcrawl-silentsleep5}# -----------------------# -----> httpx <-----write_httpx_log() {tee-a $all_found/httpx.txt| $script_path/anew $all_dedupe/httpx.txt|tee $only_new/httpx.txt}run_httpx() { $script_path/httpx -l $only_new/subfinder.txt-sc-cl-ct-location-hashsha256-rt-lc-wc-title\ -server-td-method-websocket-ip-cname-cdn-probe-xGET-silent|write_httpx_log; $script_path/notify -data $only_new/httpx.txt-bulk-providerdiscord-idcrawl-silentsleep5}# -----------------------# -----> nuclei <-----write_nuclei_log() {tee-a $all_found/nuclei.txt| $script_path/anew $all_dedupe/nuclei.txt|tee $only_new/nuclei.txt}run_nuclei() { $script_path/nuclei -ni-l $only_new/httpx.txt-shigh,critical,unknown-rl5-silent\|write_nuclei_log| $script_path/notify -providerdiscord-idvuln-silent}# -----------------------# -----> squidward <-----write_squidward_log() {tee-a $all_found/certspotter.txt| $script_path/anew $all_dedupe/certspotter.txt|tee-a $only_new/forscans.txt}run_squidward() {rm $script_path/config/certspotter/lock $script_path/squidward |write_squidward_log| $script_path/notify -providerdiscord-idcert-silentsleep3}# -----------------------send_certspotted() { $script_path/notify -data $only_new/certspotter.txt-bulk-providerdiscord-idcrawl-silentsleep5}send_starting() {echo"Hi! I am Squiddy!"| $script_path/notify -providerdiscord-idcrawl-silentecho"I am gonna start searching for new targets now :)"| $script_path/notify -providerdiscord-idcrawl-silent}dns_to_ip() {# TODO: give txt file of subdomains to get IPs from file $script_path/dnsx -a-l$1-resp-silent\|grep-oE"\b((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b"\|sort--unique}run_rustcan() {local input=""if [[ -p /dev/stdin ]]; then input="$(cat -)"else input="${@}"fiif [[ -z"${input}" ]]; thenreturn1fi# ${input/ /,} -> join space to comma# -> loop because otherwise rustscan will take forever to scan all IPs and only save results at the end# we could do this to scan all at once instead: $script_path/rustscan -b 100 -g --scan-order random -a ${input/ /,}for ip in ${input}do $script_path/rustscan -b500-g--scan-orderrandom-a $ipdone}write_rustscan_log() {tee-a $all_found/rustscan.txt| $script_path/anew $all_dedupe/rustscan.txt|tee $only_new/rustscan.txt}what_i_want_what_i_really_really_want() {# shuffle certspotter file cause why notcat $only_new/forscans.txt|shuf-o $only_new/forscans.txt $script_path/subfinder -silent-dL $only_new/forscans.txt|write_subfinder_log $script_path/notify -silent-data $only_new/subfinder.txt-bulk-providerdiscord-idsubfinder# -> empty forscans.txt> $only_new/forscans.txt# shuffle subfinder file cause why notcat $only_new/subfinder.txt|shuf-o $only_new/subfinder.txt $script_path/dnsx -l $only_new/subfinder.txt-silent-a-aaaa-cname-ns-txt-ptr-mx-soa-resp|write_dnsx_log $script_path/notify -data $only_new/dnsx.txt-bulk-providerdiscord-iddnsx-silent# shuffle dns file before iter to randomize scans a little bitcat $only_new/dnsx.txt|shuf-o $only_new/dnsx.txtsleep1cat $only_new/dnsx.txt|shuf-o $only_new/dnsx.txtwhile IFS=read-rlinedo dns_name=$(echo$line|cut-d ' ' -f1) ip=$(echo ${line} \|grep-E "\[(\b((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b)\]" \|grep-oE "(\b((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b)") match=$(echo$ip|run_rustcan)if [ !-z"$match" ]then ports_unformat=$(echo ${match} |grep-Po '\[\K[^]]*') ports=${ports_unformat//,/ }echo"$dns_name - $ip - $ports"|write_rustscan_log $script_path/notify -silent-data $only_new/rustscan.txt-bulk-providerdiscord-idportscanfor port in ${ports}doecho"$dns_name:$port"| $script_path/httpx -silent-sc-cl-ct-location\-hashsha256-rt-lc-wc-title-server-td-method-websocket\-ip-cname-cdn-probe-xGET|write_httpx_log|grep"\[SUCCESS\]"|cut-d' '-f1\| $script_path/nuclei -silent-ni-shigh,critical,unknown-rl10\|write_nuclei_log| $script_path/notify -providerdiscord-idnuclei-silent $script_path/notify -silent-data $only_new/httpx.txt-bulk-providerdiscord-idhttpxdonefidone<"$only_new/dnsx.txt"}main() { dupe_script=$(ps-ef|grep "squiddy.sh" |grep-v grep |wc-l|xargs)if [ ${dupe_script} -gt2 ]; thenecho"Hey friends! Squiddy is already running, I am gonna try again later."| $script_path/notify -providerdiscord-idcrawl-silentelsesend_startingecho"Running Squidward"run_squidwardecho"Running the entire rest"what_i_want_what_i_really_really_want# -> leaving it in for now but replace with above function#echo "Running Subfinder"#run_subfinder#echo "Running DNSX"#run_dnsx#echo "Running HTTPX"#run_httpx#echo "Running Nuclei"#run_nucleifi}setupdupe_script=$(ps-ef|grep "squiddy.sh" |grep-v grep |wc-l|xargs)if [ ${dupe_script} -gt2 ]; thenecho"Hey friends! Squiddy is already running, I am gonna try again later."| $script_path/notify -providerdiscord-idcrawl-silentelse#send_startingecho"Running Squidward"run_squidwardfi
There’s also a Python-based Discord bot that goes with this, but I’ll spare you that code—it did work back in the day 😬.
Conclusion
Back when I was a Red Teamer, this setup was a game-changer—not just during engagements, but even before them. Sometimes, during client sales calls, they’d expect you to be some kind of all-knowing security wizard who already understands their infrastructure better than they do.
So, I’d sit in these calls, quietly feeding their possible targets into Squidward and within seconds, I’d have real-time recon data. Then, I’d casually drop something like, “Well, how about I start with server XYZ? I can already see it’s vulnerable to CVE-Blah.” Most customers loved that level of preparedness.
I haven’t touched this setup in ages, and honestly, I have no clue how I’d even get it running again. I would probably go about it using Node-RED like in this post.
These days, I work for big corporate, using commercial tools for the same tasks. But writing about this definitely brought back some good memories.
Anyway, time for bed! It’s late, and you’ve got work tomorrow. Sweet dreams! 🥰😴
Have another scary squid man monster that didn’t make featured, buh-byeee 👋
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.