After building countless web scrapers over the past 15 years, I decided it was time to create something truly versatile—a tool I could use for all my projects, hosted anywhere I needed it. That’s how Scraproxy was born: a high-performance web scraping API that leverages the power of Playwright and is built with FastAPI.
Scraproxy streamlines web scraping and automation by enabling browsing automation, content extraction, and advanced tasks like capturing screenshots, recording videos, minimizing HTML, and tracking network requests and responses. It even handles challenges like cookie banners, making it a comprehensive solution for any scraping or automation project.
Best of all, it’s free and open-source. Get started today and see what it can do for you. 🔥
👉 https://github.com/StasonJatham/scraproxy
Features
- Browse Web Pages: Gather detailed information such as network data, logs, redirects, cookies, and performance metrics.
- Screenshots: Capture live screenshots or retrieve them from cache, with support for full-page screenshots and thumbnails.
- Minify HTML: Minimize HTML content by removing unnecessary elements like comments and whitespace.
- Extract Text: Extract clean, plain text from HTML content.
- Video Recording: Record a browsing session and retrieve the video as a webm file.
- Reader Mode: Extract the main readable content and title from an HTML page, similar to “reader mode” in browsers.
- Markdown Conversion: Convert HTML content into Markdown format.
- Authentication: Optional Bearer token authentication using API_KEY.
Technology Stack
- FastAPI: For building high-performance, modern APIs.
- Playwright: For automating web browser interactions and scraping.
- Docker: Containerized for consistent environments and easy deployment.
- Diskcache: Efficient caching to reduce redundant scraping requests.
- Pillow: For image processing, optimization, and thumbnail creation.
Working with Scraproxy
Thanks to FastAPI it has full API documentation via Redoc
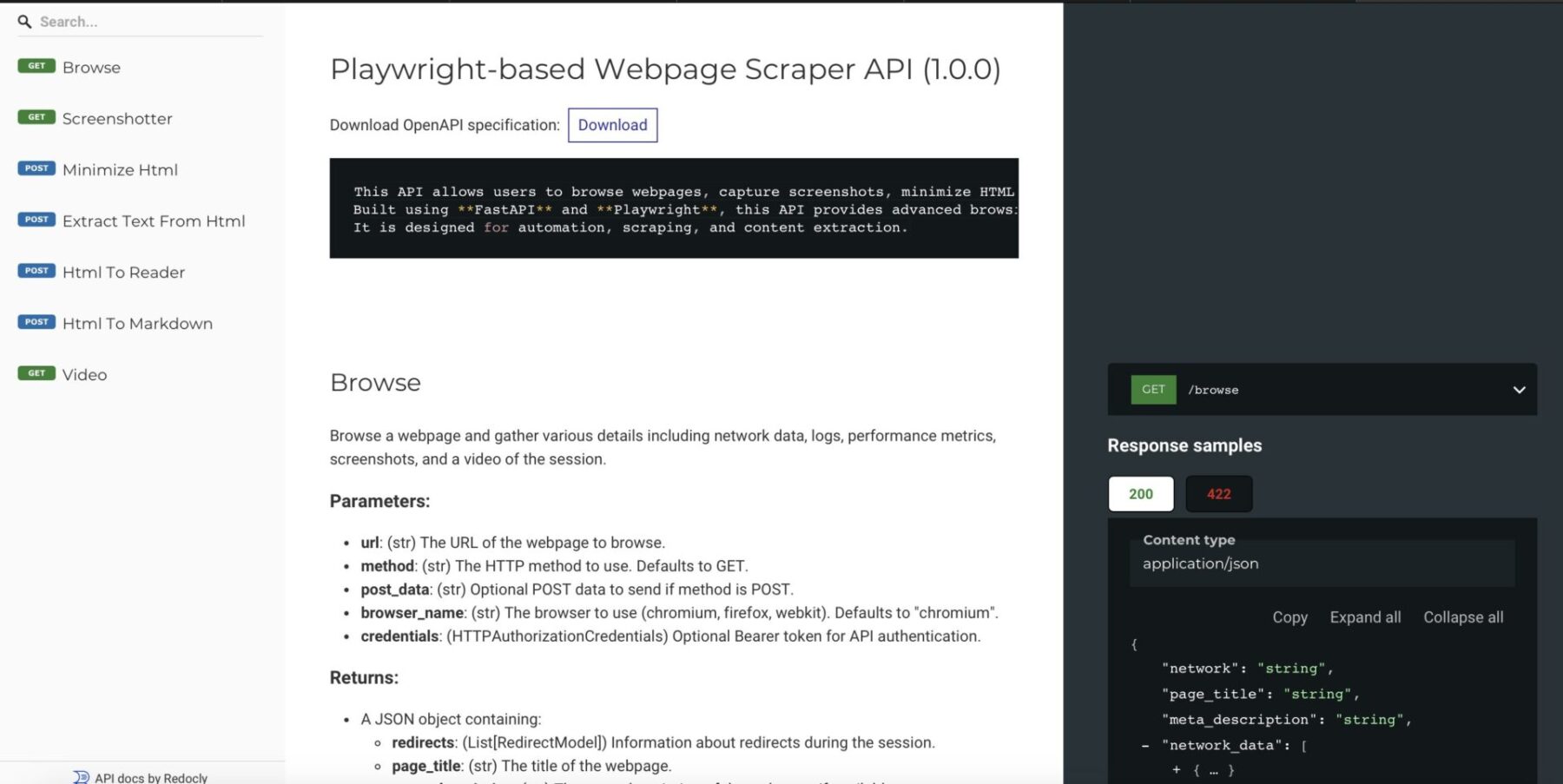
After deploying it like described on my GitHub page you can use it like so:
#!/bin/bash
# Fetch the JSON response from the API
json_response=$(curl -s "http://127.0.0.1:5001/screenshot?url=http://10.107.0.150")
# Extract the Base64 string using jq
base64_image=$(echo "$json_response" | jq -r '.screenshot')
# Decode the Base64 string and save it as an image
echo "$base64_image" | base64 --decode > screenshot.png
echo "Image saved as screenshot.png"Make sure jq is installed
The API provides images in base64 format, so we use the native base64 command to decode it and save it as a PNG file. If everything went smoothly, you should now have a file named “screenshot.png”.

Keep in mind, this isn’t a full-page screenshot. For that, you’ll want to use this script:
#!/bin/bash
# Fetch the JSON response from the API
json_response=$(curl -s "http://127.0.0.1:5001/screenshot?url=http://10.107.0.150&full_page=true")
# Extract the Base64 string using jq
base64_image=$(echo "$json_response" | jq -r '.screenshot')
# Decode the Base64 string and save it as an image
echo "$base64_image" | base64 --decode > screenshot.png
echo "Image saved as screenshot.png"Just add &full_page=true, and voilà! You’ll get a clean, full-page screenshot of the website.

The best part? You can run this multiple times since the responses are cached, which helps you avoid getting blocked too quickly.
Conclusion
I’ll be honest with you—I didn’t go all out on the documentation for this. But don’t worry, the code is thoroughly commented, and you can easily figure things out by taking a look at the app.py file.
That said, I’ve used this in plenty of my own projects as my go-to tool for fetching web data, and it’s been a lifesaver. Feel free to jump in, contribute, and help make this even better!